

The investment in AI is staggering, yet the business returns are often elusive. We see it all the time: brilliant models that perform flawlessly in isolation become brittle and unreliable the moment they touch a live production environment. When this happens, the problem is rarely the model itself. It’s the architecture underneath.
Without a resilient AI-ready infrastructure, even the most intelligent algorithms will break under the pressure of messy data and fluctuating user traffic, making ROI impossible.
Here, we want to give you a guide to designing an AI infrastructure architecture that delivers. You’ll get a plan for a system that builds the foundation for AI that scales. So, let’s learn how to build AI-ready infrastructure that brings reliable and measurable business performance.
Why AI-Ready Infrastructure Is the Foundation of AI Success
AI promises transformation, but many initiatives stall, resulting in underperforming projects and high operational costs. A brilliant model is a component, not a complete business solution, which is a common confusion when comparing AI hype vs. reality.
As AI initiatives scale, they present unique engineering challenges that standard IT infrastructure isn’t designed to handle. Data pipelines must be highly reliable to feed the model fresh, accurate information. Models themselves can “drift,” meaning their predictive accuracy changes as real-world data evolves, which calls for a system to monitor and retrain them.
Cloud costs also need careful management, as resources must scale elastically to match the variable demands of AI workloads. These are the core challenges of building a proper enterprise AI infrastructure.
Without a purpose-built foundation, this can create operational friction and slow the deployment of new capabilities. When the foundation is correctly engineered, the organization gains a predictable and efficient pathway to deploy those capabilities. Such stability allows for consistent performance and manageable operational spending.
It raises a critical question for any leader: What principles define an AI-ready infrastructure that delivers on its promise without incurring prohibitive costs? Reasonable AI infrastructure solutions are designed to answer this. Let’s find out.
What Defines a Cost-Effective AI-Ready Infrastructure
An AI-ready infrastructure is not just a collection of powerful servers. It is a purpose-built system designed to operationalize AI and turn data into business intelligence, and its long-term cost-effectiveness is determined by its design. This use of AI for business intelligence is a primary driver of its architecture and the first step toward true infrastructure intelligence.
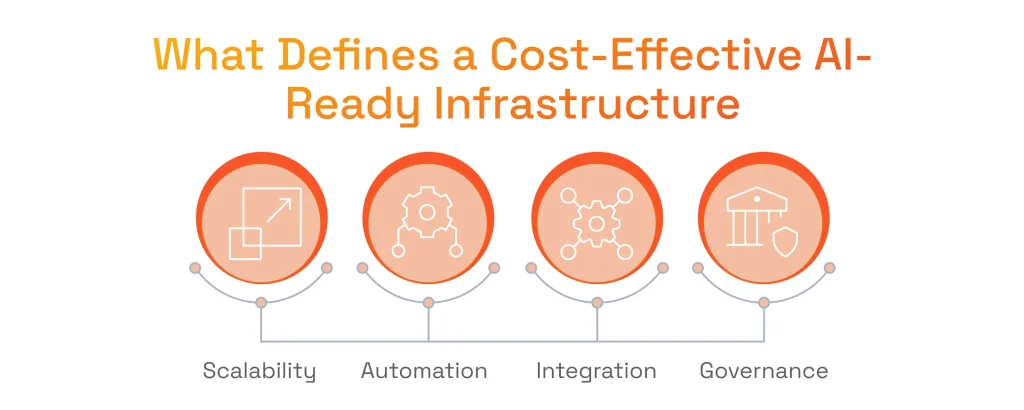
A successful AI product infrastructure is built on four interconnected principles. Each one addresses a specific technical and business challenge, and together they create a system that is both powerful and financially sound:
- Scalability: Handling variable workloads without waste.
- Automation: Ensuring consistency and freeing up high-value talent.
- Integration: Connecting teams and tools to move faster.
- Governance: Building in trust, security, and compliance.
Let’s look at how each principle functions in practice.
Scalability is essential for managing AI’s unique demands. Unlike traditional applications with predictable traffic, AI workloads are “bursty”, meaning they require massive compute power for a short training run, then sit idle. A cost-effective AI-ready infrastructure must handle this without overspending.
Your AI server architecture must automatically provision the right resources (like GPUs) for a heavy training job and, just as important, shrink them back to near-zero afterward. The elastic approach is the difference between paying for what you use and paying for an idle fleet of expensive hardware. It’s especially true for the massive compute needs of AI infrastructure for generative AI. Cost control is one of the primary cloud computing benefits when applied to AI.
Next comes automation. A mature AI product infrastructure runs on MLOps, a discipline that automates the entire lifecycle. It goes far beyond initial deployment to create a repeatable pipeline for data validation, model retraining, and A/B testing new versions. Automation removes manual and/or error-prone tasks and frees your most expensive engineering talent to focus on building new models, not babysitting old ones. A mature AI/ML infrastructure automates this work.
An AI-ready infrastructure also needs clear communication channels, which is where integration comes in. AI development is famous for its “wall of confusion” between data scientists and ML engineers. A proper AI infrastructure breaks down these technical and cultural silos by providing shared tools, APIs, and workflows. When data scientists and engineers operate from the same playbook, the feedback loop tightens, and the entire operation moves faster and more in sync with market demands.
Finally, there’s governance. Building trust is non-negotiable. It means more than just a firewall; it involves data lineage (knowing where your data came from), model auditability (knowing why a model made a specific decision), and access control. A truly cost-effective AI-ready infrastructure has security and compliance baked in from the start. The “security by design” principle is a hallmark of mature artificial intelligence infrastructure.
Building a system on these principles is a strategic financial decision. These pillars are not independent. They form an explicit formula for financial sense. The initial investment in a well-architected infrastructure is an insurance policy against the massive downstream costs of technical debt, failed deployments, and compliance violations. It’s how you build AI that pays for itself.
It’s far cheaper to build a compliant data pipeline than to halt your business and fix a non-compliant one after a breach.
Key Components of Artificial Intelligence Infrastructure
A durable AI infrastructure architecture is built as a series of distinct but interconnected layers. Each layer provides a specific capability and supports the functions of the layers above it, creating a stable and cohesive system from the ground up. Each component represents a critical stage in the AI lifecycle, and the strength of the entire system depends on how well these stages are integrated. Together, they form a complete AI infrastructure ecosystem.
Let’s review the key components of AI product infrastructure.
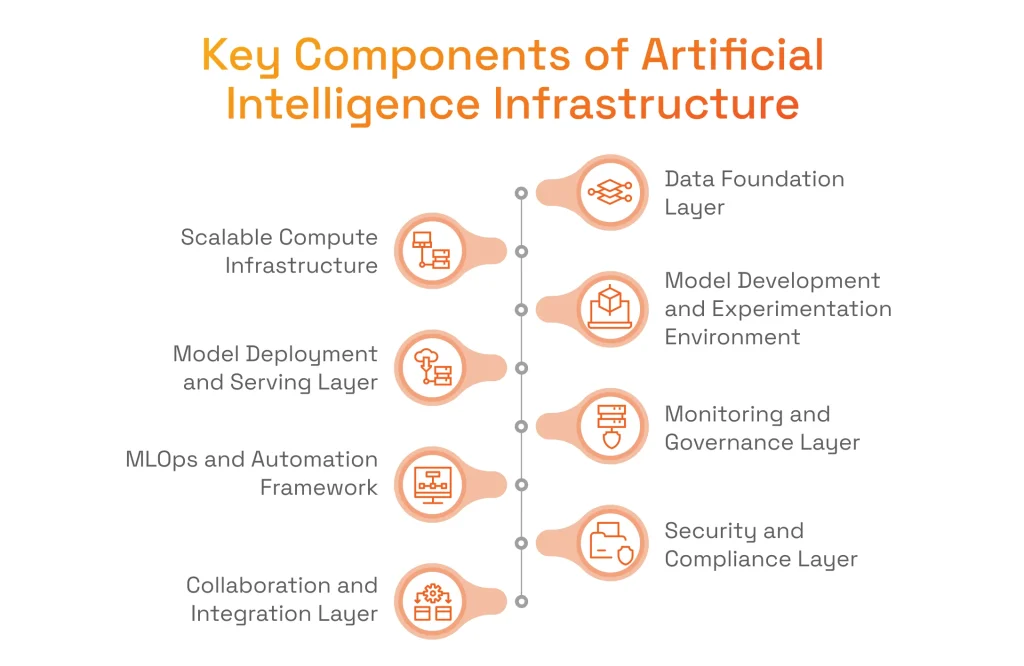
Data Foundation Layer
The entire structure rests on the data foundation layer, which is the centralized system responsible for the integrity of all data used for AI. It handles data ingestion, storage, and preparation.
The layer tames raw, siloed data from across the business, running data pipelines (ETL/ELT) and feature engineering to transform it into a high-quality format. Its purpose is to provide a single source of truth, ensuring every model is built on clean, consistent, and reliable data because an AI’s accuracy is a direct reflection of its data quality.
Our focus for a legacy investment platform re-development was on this very step, where we reengineered data architecture as a solid foundation for all subsequent AI-driven analytics. Building this needs a cohesive enterprise data strategy, which itself is one of the foundational AI infrastructure requirements for enterprises.
Scalable Compute Infrastructure
The scalable AI infrastructure provides the raw power for the entire system. It’s an elastic pool of compute resources that AI workloads draw from: CPUs, GPUs, TPUs, processing data from traditional databases as well as real-time streams from AI and IoT devices.
AI workloads are often intense but intermittent. So, the key attribute here is elasticity. The infrastructure automatically allocates the right amount of power for a given task and releases it afterward.
An elastic infrastructure allows for rapid experimentation and distributed training without the cost of maintaining idle hardware. Such a design prevents resource waste and controls costs, as we demonstrated with an AI-powered ticketing system, which we transformed with a scalable cloud architecture that processes millions of events while optimizing infrastructure costs.
Model Development and Experimentation Environment
This is the controlled environment where data scientists build, train, and version models. In this version-controlled collaborative space, data scientists can methodically design, train, test, and track models using tools such as JupyterHub or MLflow.
It brings methodical rigor to AI development, which helps perform reproducible, transparent, and auditable experiments. A structured approach like this ultimately shortens the cycle from an initial idea to a validated production-ready model by making it easy to track what works, what doesn’t, and why.
Model Deployment and Serving Layer
Great ideas are useless if they can’t reach the public. A validated model only creates value when it is operational. The deployment layer consists of an automated CI/CD pipeline that packages models and deploys them as scalable low-latency APIs or batch processes. A well-designed serving layer ensures that predictions are delivered with low latency and high availability.
An automated serving layer shortens time-to-market and reduces the risks associated with manual deployments. We implemented this for a packaging manufacturer, automating deployment pipelines to move from testing to production with zero downtime.
Monitoring and Governance Layer
Once deployed, a model’s performance must be continuously tracked. This layer is a suite of tools for monitoring performance metrics, data drift, prediction bias, and resource consumption. For critical decisions, this often includes a human-in-the-loop approach to validate and correct model outputs.
Models are not static. They can degrade as real-world data patterns change, and this “drift” is a silent killer of AI ROI. The system should act as an early warning, detecting performance issues before they impact business outcomes. It is essential for maintaining trust and reliability, and for ensuring the application remains compliant with its operational and regulatory boundaries.
Serhii Leleko
ML & AI Engineer at SPD Technology
“A model that can’t be explained or governed is a liability. The monitoring layer is where you build trust, proving to users and regulators that your AI is fair and accurate.”
MLOps and Automation Framework
MLOps is the operational logic that connects and standardizes all other layers. It is the set of procedures and technologies that automates the end-to-end AI lifecycle: from data ingestion to model retirement.
Operating AI at scale is not feasible without MLOps. It applies DevOps principles to the machine learning process to ensure consistency and reproducibility while reducing manual intervention. The framework provides an efficient way to manage an extensive portfolio of models, enabling you to update and deploy them with speed and confidence. Building and maintaining it requires deep MLOps expertise. This is often where professional AI infrastructure services deliver the most value through automated pipelines.
Wondering how to find a partner with this deep MLOps knowledge? Read our guide on the top AI development companies.
Security and Compliance Layer
Security must be integrated throughout the AI lifecycle. This governance is a key component of a complete data management framework. A secure AI infrastructure is built on this pervasive set of tools and policies for identity management, access control, data encryption, regulatory alignment, and vulnerability scanning. With regulations like GDPR, protecting sensitive data is a core requirement, particularly for applications in AI for financial technology.
We partnered with a European investment platform whose legacy system was experiencing difficulty in meeting modern compliance standards such as PSD2 and GDPR. We engineered a new secure data architecture that not only unified the client’s fragmented data but also baked in security and compliance from the ground up.

This foundation now securely handles all transactions and data, protecting the client’s assets and ensuring compliance with regulatory requirements, a mandatory step before implementing any advanced AI.
Collaboration and Integration Layer
AI development involves multiple teams. The collaboration layer provides shared platforms, APIs, and SDKs that help data scientists, ML engineers, and application developers work effectively together. It breaks down organizational silos by creating a common technical ground, or a “common language,” between teams that often have different priorities.
When teams can easily integrate their work, the feedback loop tightens, and the entire delivery process becomes faster and more aligned with overarching business objectives.
Common Challenges in Building AI Product Infrastructure (and How We Solve Them)
Even the best AI strategy can fall apart during implementation. The challenges of building a real AI product infrastructure are often underestimated, which leads to friction, delays, and budget overruns. We specialize in finding these friction points and engineering the solutions.
In our experience helping enterprises build AI infrastructure solutions, we’ve seen the same roadblocks appear time and again. Let’s talk about them.
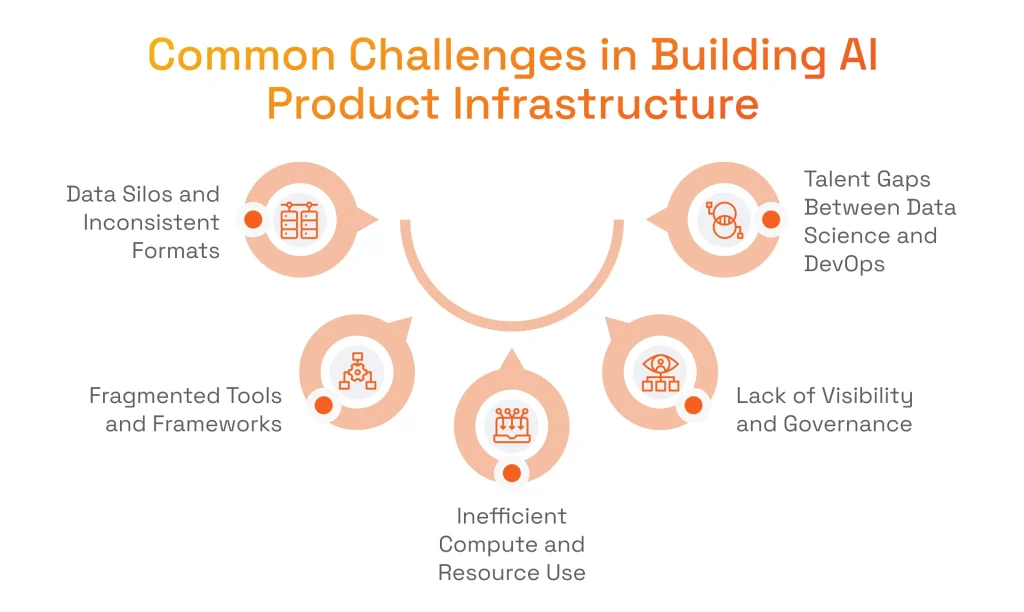
Challenge #1: Data Silos
Your data is your biggest asset, but it’s often locked away in different departments. When data is scattered, your models are built on shaky ground. We solve this by designing unified data architectures and metadata layers to create a single reliable source of truth for all your AI projects. A clear data management strategy is the first step to solving this.
How does a modern data foundation power more than just AI? Read our guide on data infrastructure and analytics.
Challenge #2: Tool Fragmentation
A “best-of-breed” tool strategy can easily become a worst-case-scenario bottleneck. We address this by standardizing on a flexible MLOps framework. We integrate your preferred tools into one cohesive CI/CD pipeline, removing the friction from your workflow.
Challenge #3: Inefficient Compute Spend
Nothing stops an AI project faster than an uncontrolled cloud bill. We manage this by implementing smart workload orchestration and autoscaling. Your systems get the power they need for heavy training, then scale down immediately, so you only pay for the compute power you use.
Challenge #4: Governance Blind Spots
If you can’t explain your model’s decision, you can’t trust it in production. We eliminate these “black box” problems by building monitoring, audit logs, and automated compliance checks directly into your pipelines, giving you full visibility.
Challenge #5: The DevOps/Data Science Divide
The gap between data science and engineering is where many AI projects fail. We close this gap with integrated collaboration platforms and shared workflows. This gets your teams speaking the same language and working toward the same goal.
Curious how solving these data challenges translates directly into business value? Learn more about data engineering for product-led growth.
How SPD Technology Builds Artificial Intelligence Infrastructure That Drives Business Growth
Our value proposition is straightforward: we design artificial intelligence infrastructure that delivers on its promise. We focus on turning your AI investments into measurable business value, fast.
This begins with a business-driven design. We don’t lead with a rigid tech stack; we lead with your objectives. Are you focused on reducing operational costs? Getting to market before a competitor? Meeting new compliance demands? Our AI infrastructure architecture is designed to meet those specific outcomes. We specialize in building these custom AI solutions, including developing the entire AI infrastructure stack to support them.
We make it a reality through seamless MLOps integration. We connect data, model training, and deployment pipelines into one automated end-to-end system, giving you the speed and reliability to update and deploy new models in days, not months. This is the goal of our AI infrastructure services.
In today’s environment, risk management is non-negotiable. We build security and compliance from the start. We’re also fluent in the complexities of GDPR, SOC 2, and HIPAA to ensure your infrastructure is stable and secure.
Our experience in FinTech, HealthTech, LegalTech, SaaS, and Logistics, among others, means we have cross-industry expertise in scaling and cost-efficiency challenges. Our case studies show the proven delivery results: clients with measurably reduced cloud costs, faster deployment cycles, and a clear, positive return on their AI investment.
AI Success Starts With the Right Infrastructure: Build Yours Now
Your model doesn’t define AI success in isolation. It’s defined by the infrastructure that delivers that model’s insights reliably and at scale. A scalable and cost-effective AI-ready infrastructure is what separates a promising experiment from a profitable product. This is how you turn raw data into measurable business outcomes.
Don’t let infrastructure challenges stall your progress from initial data strategy to full-scale deployment. Discover how SPD Technology’s AI/ML development services help you design and build the right AI product infrastructure for long-term success. Contact our team to discuss your project and secure the technical expertise needed to scale with confidence.
FAQ
What industries benefit most from AI-ready infrastructure?
Any industry with large data volumes. We see high impact in FinTech (fraud), HealthTech (diagnostics), logistics (optimization), and SaaS (personalization). The principles of scalability and automation apply universally.
Can small and mid-sized businesses adopt AI-ready infrastructure?
Absolutely. Cloud platforms and open-source tools make it accessible. The key is to apply the same principles (automation, governance) at a scale that aligns with your budget and business goals.
How does AI-ready infrastructure differ from traditional IT infrastructure?
Traditional IT is static and built for predictable workloads. AI infrastructure is data-centric and dynamic. It prioritizes GPU/TPU accelerators, relies on heavy automation (MLOps), and is built for massive fluctuating data flows.