
Predictive customer analytics uses AI and ML to forecast purchase intent, churn risk, and demand from behavioral and transactional data. McKinsey research shows that retail companies leading in digital and AI deliver 3x greater total shareholder returns than peers, with predictive analytics driving this gap by converting raw data into real-time pricing, retention, and demand decisions. The primary barrier is data readiness: Gartner reports that 63% of organizations lack or are unsure they have the right data management practices for AI, making data quality the deciding factor between deployments that deliver ROI and those that get abandoned.
Retail businesses have always strived to capture as much customer attention as possible, which is why they have continually worked to predict demand and align it with adequate supply. Today, with artificial intelligence (AI) and machine learning (ML) boosting business operations, competition for customers has grown even more intense. And with good reason: CPG and retail companies that lead in digital and AI are already showing three times greater total shareholder returns compared with their peers in the sector, according to McKinsey. Predictive customer analytics is one of the core drivers of this gap since by forecasting demand, identifying high-value customers before they churn, and enabling personalized pricing and offers in real time, it turns raw behavioral data into decisions that directly protect margin and accelerate revenue growth.
In this article, we will explore why predictive customer analytics helps businesses achieve such excellence, discuss its use cases and benefits, and address the implementation challenges businesses may encounter.
The Growing Importance of Customer Predictive Analytics
The predictive analytics software market, which was valued at $5.29 billion in 2020, is projected to reach $41.52 billion by 2028, according to Statista. This rapid growth indicates a recognition among businesses of all sizes that leveraging historical and real-time data and processing it with AI/ML to predict customer behavior is essential for accommodating customer needs.
The business impact of Big Data lies at the core of this opportunity. Now, when organizations collect massive volumes of information from sources such as eCommerce transactions, social media interactions, and IoT devices, they can also translate it into actionable insights. Fed to AI, this data can be interpreted for improving supply chain operations, fine-tuning marketing campaigns, and adjusting inventory according to customer demand.
Thanks to AI technologies that analyze customer data and predict future behavior, customer retention becomes easier than before. This is due to predictive customer analytics, powered by AI and machine learning, which can identify behavioral patterns and personalize offers and experiences with pinpoint accuracy. In this manner, businesses reduce customer churn among existing customers while also boosting brand loyalty. The impact is the increase of customer satisfaction, sales growth, and improved revenues.
Additionally, analytics can power business intelligence (BI), which becomes essential as eCommerce operations grow in scale and complexity. Combining analytics with BI and modern AI tools allows retailers to gain granular insights into purchase patterns, supply chain efficiencies, and marketing performance. These insights, in turn, inform data-driven decisions, helping teams analyze data to determine which products to promote, when to adjust pricing, and how to better engage customers across channels. With these capabilities, businesses become more competitive and secure their place in the market.
Discover the insights eCommerce business intelligence solutions provide to help you better understand your customers and unlock new opportunities!
The Game-Changing Benefits of Predictive Analytics Customer Behavior
With analytics, customer behavior can be analyzed with a much greater level of accuracy. This unlocks a whole new array of benefits for businesses to drive revenue growth and customer engagement.
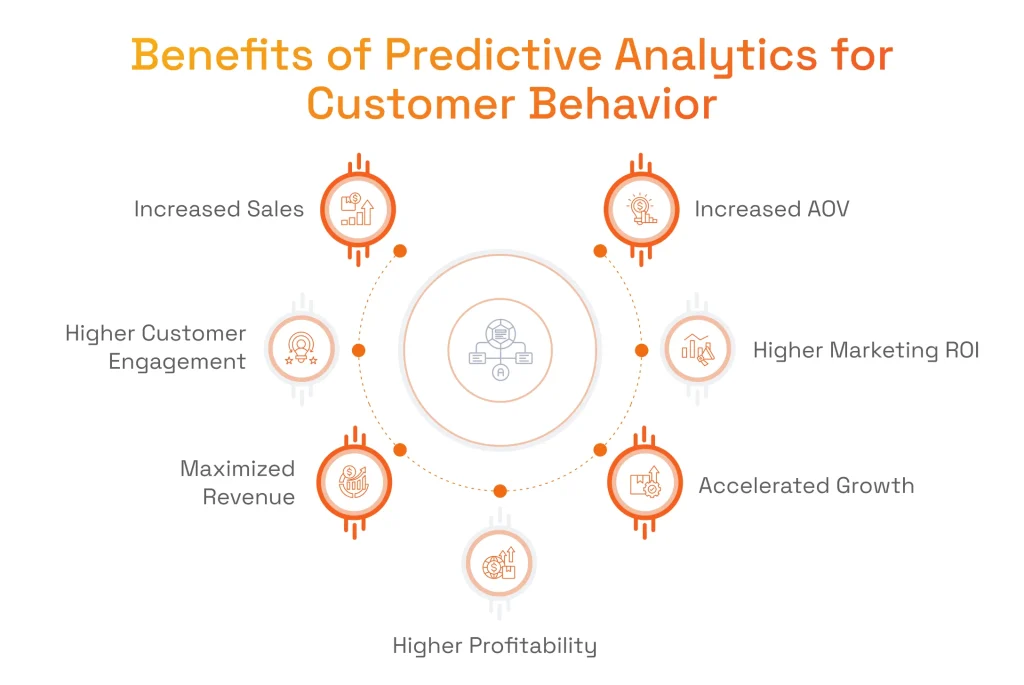
- Increased Sales Through Anticipated Demand: Businesses get the possibility to leverage AI demand forecasting to anticipate customer needs and stock inventory accordingly, using historical data and real-time signals to spot market trends. This reduces the risk of overstocking or understocking and supports smarter data analysis to save costs.
- Higher Customer Engagement Through Hyper-Personalization: By analyzing customer data, like past purchases, browsing habits, and demographics, AI-powered customer behavior analysis pinpoints the most relevant content or products for each individual, based on hidden patterns in behavior. This helps predict future customer actions, improving click-through rates and conversions as customers interact across channels.
- Maximized Revenue with Dynamic Pricing: Predictive models generate real-time insights into market fluctuations, competitor actions, consumer behavior, and demand shifts. Using data analytics, businesses can adjust pricing strategies more quickly and predict future behaviors to attract more customers and protect margins.
- Higher Profitability by Focusing on High-Value Customers: AI customer analytics enables identifying customers with the highest lifetime value and segmenting customers based on potential spend and purchase propensity. This supports better budget allocation, lowering marketing costs by prioritizing high-value segments.
- Accelerated Growth by Spotting Emerging Trends: ML-driven data analytics can detect evolving consumer preferences, market trends, and new niches before they hit the mainstream by uncovering hidden patterns in performance and demand signals. Acting early helps businesses create products, services, or campaigns that match emerging needs and boost sales.
- Higher Marketing ROI by Reducing Waste: Predictive models refine targeting by using customer behavior analysis and campaign performance data analysis to focus spend on the most relevant audiences. This reduces wasted ad budgets on uninterested consumers, lowering acquisition costs and increasing conversion rates.
- Increased Average Order Value Through Intelligent Suggestions: Analytics helps businesses understand customer preferences, buying patterns, and context using customer data and historical data. This powers personalized cross-sell and upsell recommendations, driving higher average order value, increased sales, and stronger revenues.
How a Predictive Analytics Platform Works for Spotting Customer Behavior
The process of predicting customer behavior is powered by the combination of predictive analytics and machine learning in retail. Analytics enables predictive behavior modeling through data analysis, where data scientists and ML engineers use AI tools to build and train machine learning models. Training typically starts when teams gather data from multiple sources and feed large volumes of historical data into these models. As a result, models can identify patterns in past actions and predict future customer behavior with greater accuracy.
Once eCommerce businesses have this prediction data, they can turn it into data-driven insights about user behavior and customer interactions across the customer journey. These insights help teams identify patterns and apply them to AI-driven customer segmentation, personalization, dynamic pricing, and predictive retargeting. Thus, businesses commit to delivering more personalized experiences, improving customer satisfaction, and helping retain existing customers over time.
To allow customer segmentation, predictive modeling is capable of analyzing customers behavior, demographics, devices used, amounts of money spent for purchases to define separate groups of customers. These groups usually share similar purchasing patterns and preferences. This is why it is possible to later fine-tune marketing efforts or product recommendations in the store based on lifestyle values, spending habits, cultural similarities, etc.
According to McKinsey’s, advanced AI-enabled personalization drives revenue and margin impact simultaneously. So, if it is required to equip the business strategy with personalized marketing approaches, predictive modeling can scrutinize individual customer preferences and past behavior types. Those can include frequency and preferences of purchases, search queries, products viewed or abandoned in the cart. With that information, it is possible to craft personalized product recommendations, send targeted marketing messages, and adjust website content and product listings.
Predictive modeling also powers dynamic pricing. To do so, such factors as product demand, competitor prices, or even weather patterns are analyzed to craft adjustments to pricing strategies or come up with limited-time offers and special deals.
Finally, predictive retargeting is also possible thanks to predictive modeling for customer behavior. For that, search, browsing and purchase histories are scrutinized under analysis. In this case, eCommerce businesses are allowed for targeted marketing campaigns such as abandoned cart recovery, win-back campaigns, upselling or cross-selling.

Serhii Leleko
AI&ML Engineer at SPD Technology
“Predictive modeling is extremely valuable for eCommerce. It contributes to understanding customer behavior and adapting to it, which paves the way to more relevant marketing approaches and lead to improved customer satisfaction and business longevity.”
AI Customer Behavior Analysis Examples for Behavior Patterns Identification
In order to build an eCommerce website with AI for customer behavior prediction, businesses opt for artificial intelligence and data analytics. Coupled together, these technologies collect and analyze customer data to offer deeper insights into consumer behavior.
This combination unlocks a multitude of actionable insights, which, in turn, allows companies to make data-driven decisions at every stage of the customer journey. AI and data analytics services refine the eCommerce experience for both the brand and the consumer. Below are some key areas where AI-driven predictive insights can transform online retail strategies:
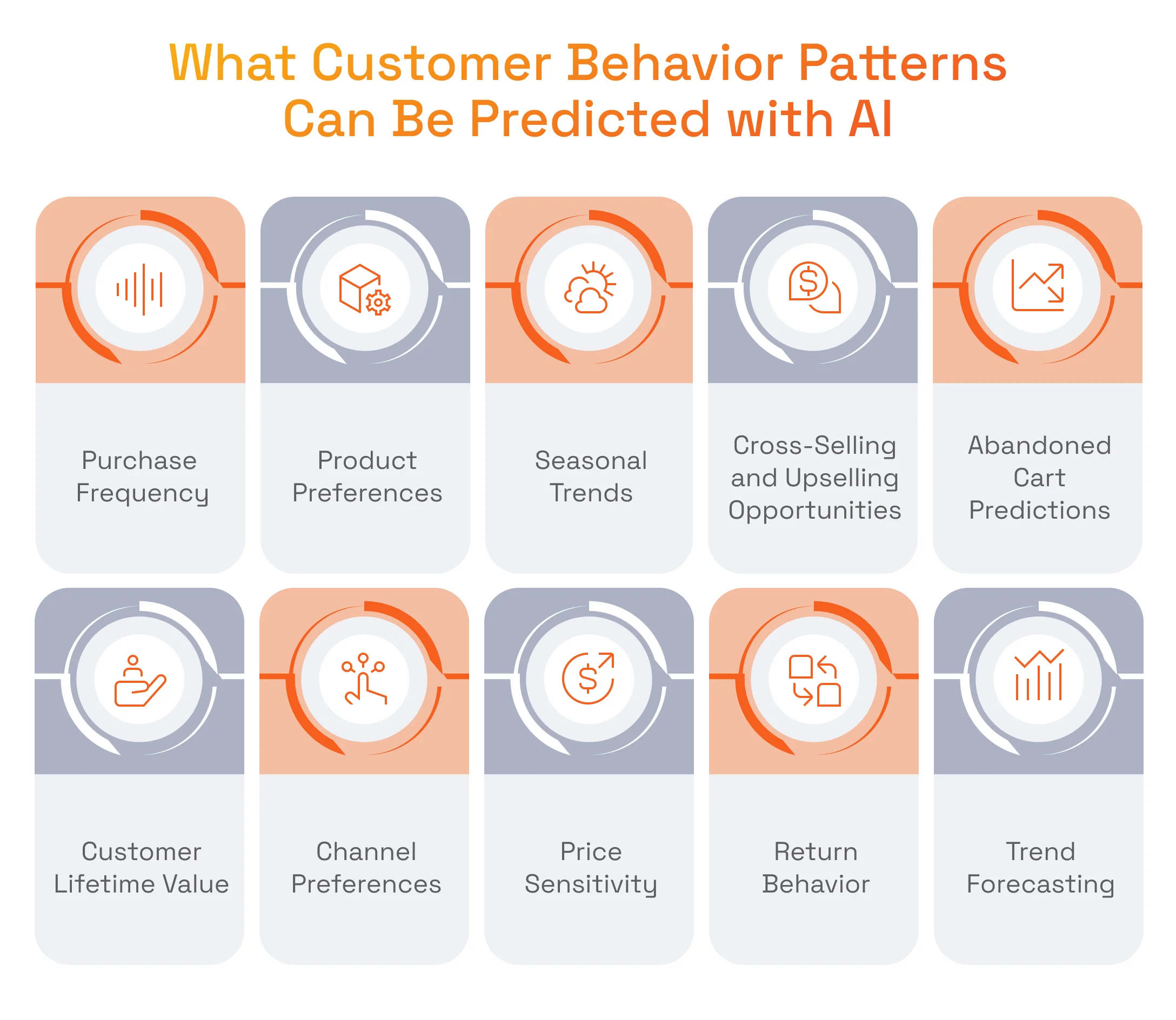
Customers interact with online stores in a consistently predictable manner. Therefore, it is possible for AI to accurately predict:
- Purchase Frequency: Using customer behavior analysis, AI tools, and data analytics, businesses can forecast when a customer will return to buy again by learning from historical data and historical sales data, turning it into actionable insights.
- Product Preferences: By evaluating browsing behavior and past purchases, AI delivers actionable insights into products customers are likely to buy next, supporting more personalized experiences and a stronger customer experience.
- Cross-Selling and Upselling Opportunities: Data on previous purchases and browsing history helps AI understand product affinities and recommend relevant add-ons based on customer interactions, increasing basket size while maintaining a positive customer experience.
- Abandoned Cart Predictions: AI can spot why customers abandon carts, such as complex checkout, limited payment or delivery options, or price sensitivity, so teams can improve the customer experience and reduce drop-offs.
- Customer Lifetime Value: AI is capable of segmenting customers based engagement, buying habits, and purchase frequency to estimate customer lifetime value and identify which customers are more likely to cancel subscriptions, supporting retention and customer loyalty.
- Channel Preferences: By analyzing how customers respond to emails, social media messages, or blog articles, AI reveals which channels work best for each segment, helping with improving marketing strategies and optimizing outreach based on customer interactions.
- Price Sensitivity: Customer behavior analysis helps identify price-sensitive shoppers and tailor recommendations and offers accordingly, enabling more relevant personalized experiences.
- Return Behavior: Thanks to analyzing return data, AI can highlight products with higher return likelihood and use anomaly detection to flag potentially fraudulent returns, improving the overall customer experience.
- Trend Forecasting: By evaluating browsing behavior alongside market research signals like social media trends, AI can forecast which products will be in higher demand soon, reflecting shifts in consumer behavior.
- Seasonal Trends: AI identifies seasonal demand fluctuations by analyzing historical sales data across holidays, back-to-school periods, and fashion cycles, providing actionable insights for inventory and campaign planning.
Want to know how machine learning works for demand forecasting in retail?
Discover the details in our article!
The Process of Customer Analytics Trends and Behavior Modeling with AI Technologies
Building predictive behavior models is all about the synergy of quality data and clearly defined goals for behavior analysis. When businesses want to predict customer behavior for propelling their retail marketing efforts, the following process of developing appropriate models will be a part of eCommerce development services.
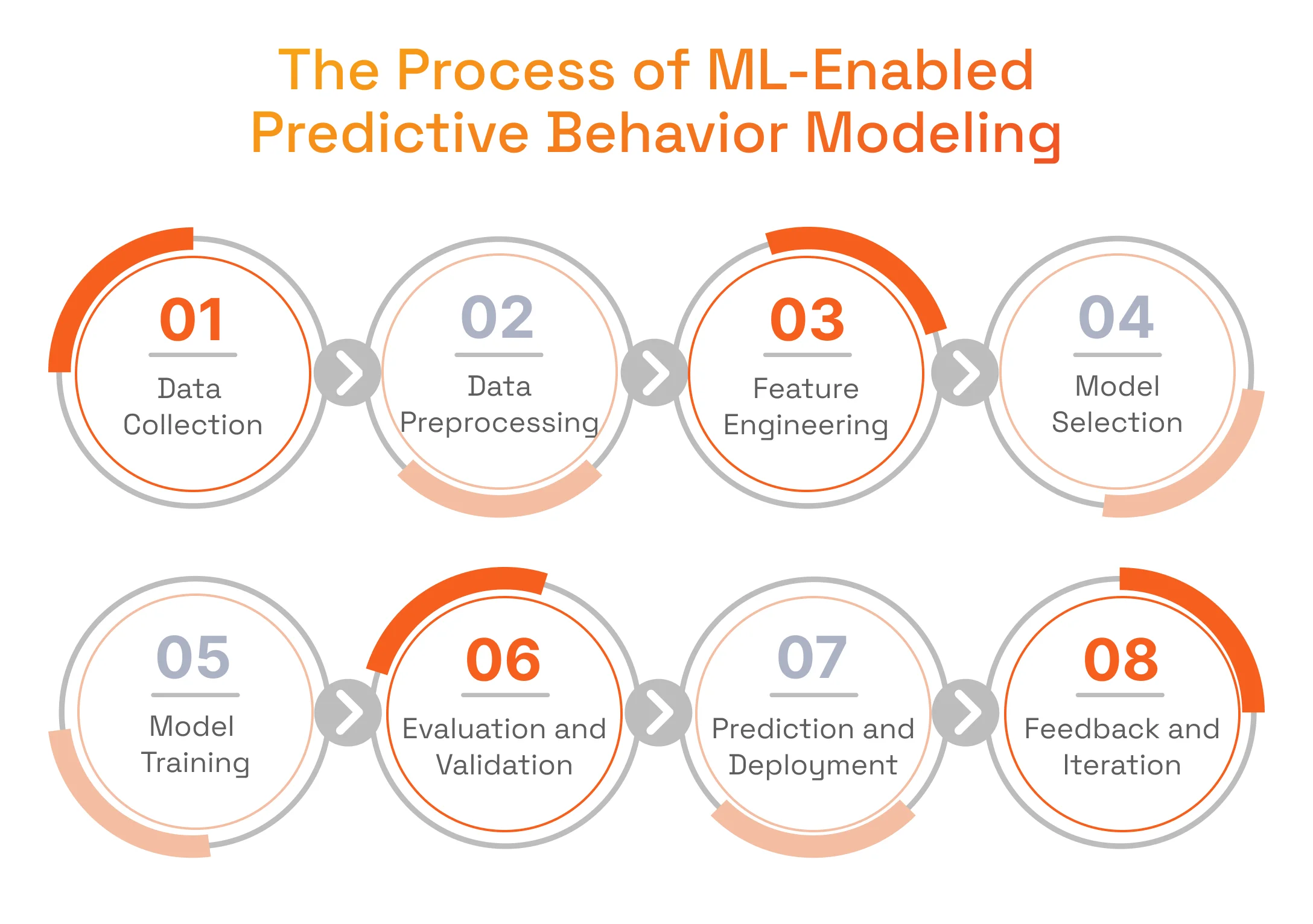
Data Collection
The process begins with the collection of relevant data about customer behaviors. This data must be gathered following privacy regulations (e.g. GDPR) to establish the lawful basis for predictive insights on consumer behavior. The following data is usually collected:
- Customer Demographics: Age, location, gender, income;
- Website Activity: Product views, search history, time spent on pages, clicks;
- Purchase History: Products purchased, order value, frequency of purchases;
- Reviews and Ratings: Consumer feedback or customer surveys on products;
- External Data: Social media sentiment, market trends.
Data Preprocessing
When data is collected, it doesn’t mean it is ready for analysis. Moreover, it is considered to be raw and most likely to contain errors or inconsistencies. Therefore, the next step of predictive modeling is preprocessing of this data. This helps to clean and prepare it for analysis. During this stage, data scientists and ML engineers handle missing values, identify and correct errors in data entries, and ensure data is consistent in terms of format and units. Ensuring the quality and consistency of data points in AI systems is crucial for accurate predictive modeling, as analyzing numerous data points allows for more precise customer profiling and tailored engagement strategies.
Data cleaning is followed by data normalization or standardization. This technique is responsible for scaling numerical features to a common range. As a result, all features contribute equally to the model’s performance, leading to more accurate predictions for future marketing efforts.
Feature Engineering
Deriving significant characteristics or variables from the raw data to reflect various important aspects of how customers interact with the eCommerce business is the next step in predicting customer behavior. In feature engineering, new variables are made from preexisting data, current features are combined to generate new informative ones, or the most pertinent characteristics that help with the prediction task are selected.
The goal of feature engineering is to create features for models that may be used from data originating from unstructured sources, such as text and images. Data points extracted from these unstructured sources are transformed into features for predictive modeling in AI technologies, enabling more granular and accurate analysis of customer behavior. Using image-to-text and image recognition technologies to eliminate superfluous words and photos from product descriptions was one of our eCommerce initiatives. Our customer was able to expand their product range and boost traffic by 56% by seamlessly incorporating over 1,000,000 products with precise and pertinent item descriptions.

Model Selection
During this stage of AI/ML development services, ML engineers decide which machine learning models will be the most suitable for customer behavior prediction tasks. For that, they define the nature of prediction tasks (e.g. suggest additional products to buy, include in marketing emails, etc.). Then, they evaluate characteristics of the data. And afterwards, they can finally choose the right algorithms based on the findings from the previous stages.
Some of the commonly used algorithms for predictive behavior modeling include regression models, decision trees, random forests, and neural networks. The table below maps each model to its optimal use case, data requirements, and key trade-offs to guide that choice before diving into the details.
Algorithm | Best Use Case | Data Type | Why Choose It | When to Avoid It |
|---|---|---|---|---|
Regression Models | CLV prediction | Structured, numerical (purchase history, order value, demographics) | Produces interpretable outputs that map directly to revenue forecasting; easy to validate against business KPIs | When customer behavior is non-linear or driven by complex interaction patterns that simple regression cannot capture |
Decision Trees | Customer segmentation | Structured, mixed (demographics, purchase history, website behavior) | Generates human-readable segmentation rules that non-technical stakeholders can understand and act on | Large datasets with many features — decision trees overfit without careful tuning and pruning |
Random Forests | Churn prediction | Structured, mixed (login frequency, purchase history, support interactions) | High predictive accuracy; handles missing data, class imbalance, and correlated features without extensive preprocessing | When model interpretability is required — random forest outputs are difficult to explain to business teams or regulators |
Neural Networks | Purchase intent prediction | Structured and unstructured (clickstreams, images, text, abandoned cart data) | Captures complex non-linear behavioral patterns in real time; improves accuracy as data volume grows | Small datasets or compliance-sensitive contexts where explainability of predictions is a regulatory requirement |
Algorithm
Regression Models
Decision Trees
Random Forests
Neural Networks
Best Use Case
CLV prediction
Customer segmentation
Churn prediction
Purchase intent prediction
Data Type
Structured, numerical (purchase history, order value, demographics)
Structured, mixed (demographics, purchase history, website behavior)
Structured, mixed (login frequency, purchase history, support interactions)
Structured and unstructured (clickstreams, images, text, abandoned cart data)
Why Choose It
Produces interpretable outputs that map directly to revenue forecasting; easy to validate against business KPIs
Generates human-readable segmentation rules that non-technical stakeholders can understand and act on
High predictive accuracy; handles missing data, class imbalance, and correlated features without extensive preprocessing
Captures complex non-linear behavioral patterns in real time; improves accuracy as data volume grows
When to Avoid It
When customer behavior is non-linear or driven by complex interaction patterns that simple regression cannot capture
Large datasets with many features — decision trees overfit without careful tuning and pruning
When model interpretability is required — random forest outputs are difficult to explain to business teams or regulators
Small datasets or compliance-sensitive contexts where explainability of predictions is a regulatory requirement
Each of these algorithms addresses a distinct prediction problem, and understanding the mechanics behind them (how they process data, where they excel, and where they fail) is what separates a well-calibrated model from one that produces unreliable outputs in production.
Regression Models
Use Case: Customer Lifetime Value (CLV) Prediction
Regression methods, including logistic and linear regression, work well for predicting CLV. These models forecast the total income a customer is anticipated to create over the course of their lifetime with the eCommerce business by analyzing customer data, including historical purchase history, demographics, and product preferences.
Regression models open the following possibilities for the marketing strategy in retail:
- Identifying customers who bring the most value to the business to personalize marketing techniques for their retention;
- Optimizing marketing cost thanks to centering marketing and sales efforts on segments of customers with high CLV;
- Creating reward campaigns or customizing loyalty programs for important clients.
Decision Trees
Use Case: Customer Segmentation
Decision trees can check demographics, purchase history, and website behavior to produce specific rules and criteria for meaningful segmentation. Consequently, segments will contain customers with similar behaviors and preference or purchase characteristics.
Using decision trees for customer segmentation can offer:
- Executing marketing strategies targeted specifically for certain customer segments;
- Creating customized product bundles and upsell/cross-sell tactics for various market categories;
- Designing focused email campaigns that offer pertinent product recommendations for every market segment.
Random Forests
Use Case: Churn Prediction
Login frequency, history of purchases, and interaction with support can be analyzed with random forests. Along with aforementioned customer engagement metrics, these algorithms also evaluate demographics and subscription details among other factors. In such a way, eCommerce companies can get insights into reasons behind subscription cancellation.
With the work of random forests, retailers can fine-tune their marketing efforts to make customers stay thanks to:
- Defining customers who are likely to churn and offering them targeted incentives;
- Offering personalized promotions for at-risk customers;
- Improving customer retention rates and reducing customer acquisition costs.
Neural Networks
Use Case: Customer Purchase Intent Prediction
Deep learning models like neural networks help with detecting purchase intent. They analyze browsing behavior thanks to tracking clicks, time spent on pages, interactions with products, items in abandoned carts to understand what customers prefer. Also, these algorithms provide insights into demographic data, including gender and age. With all the data collected and analyzed, they can indicate whether a customer is likely to purchase a product or not.
Benefits of using neural networks for predicting customer behavior include:
- Displaying personalized product recommendations based on real-time purchase intent;
- Optimizing product placement in the digital store to show only relevant items to customers with high buying intent;
- Reducing cart abandonment rates by offering targeted incentives at the checkout stage.
Serhii Leleko
AI&ML Engineer at SPD Technology
“Choosing the right model to predict behavior requires understanding customers’ goals. We pay attention to data: structured data works well with most models, while unstructured data might need pre-processing. Interpretability is also important. If you need to understand why a customer might churn, simpler models like decision trees are better than complex neural networks.”
Model Training
After data scientists and ML engineers choose the appropriate models for customer behavior analysis, they feed models with the prepared data to learn the patterns and relationships between features and target variables. During training, data is strategically split into two sets: training data (used for model learning) and a testing set (used for evaluation). This split helps to detect overfitting, the case where the model memorizes the training data too well but performs poorly on unseen data. Models for AI systems are trained and validated using numerous data points, which ensures greater accuracy and reliability in analyzing customer behavior.
Next, the types of machine learning models are used to determine which particular training pipeline to choose. In order to maximize performance, hyperparameters, meaning the parameters that govern the behavior of the models, are also changed. In order to reduce prediction errors, models need the modification of their internal parameters after learning patterns from the training set.
Evaluation and Validation
Once trained for customer behavior analysis, the model performance needs to be evaluated. This can be done on the unseen testing data set. Such an approach allows data scientists to see if models can correctly generalize to new data. Also, this helps detect overfitting.
Classification, regression, and AUC-ROC curve are commonly used metrics for evaluating model performance. They are used to check the results of predicting customer categories, numerical values, or assessing model imbalanced datasets respectively. Thanks to evaluation, it becomes possible to see if there are any weaknesses in the models before deployment.
Prediction and Deployment
If the evaluation stage went successfully, and machine learning performs well, it means they are ready for deployment and can be integrated into the eCommerce website for analyzing consumer behavior. Once deployed, models take in features representing consumer behavior data and output predictions about their future actions or decisions.
There are two main ways this can be used:
- The store can generate real-time predictions, which contributes to personalized recommendations or discounts. With real-time prediction, customers are more likely to take immediate action and buy right away.
- The store can collect numerous predictions and use them for reporting, predicting future trends, or meticulously crafting marketing campaigns.
Feedback and Iteration
Customer behavior is not stable, so it’s essential to continuously monitor model performance over time and make adjustments when needed. In addition, external factors can rapidly change the eCommerce environment: new merchants entering the market, emerging trends that shift customer needs, and sudden changes in the global economy that affect purchasing power. Addressing these changes often requires ongoing market research and the ability to analyze consumer behavior when fine-tuning ML models.
To ensure models provide relevant predictions, you should monitor performance through a feedback loop that incorporates customer feedback, customer engagement signals, and (when available) customer sentiment and customer sentiment data. This approach enables more accurate data-driven decisions and helps identify areas for improvement, such as feeding fresh data for re-training, adjusting hyperparameters, or developing new models to meet business requirements more efficiently.
Main Considerations Before Implementing Predictive Analytics in Customer Service
Before embarking on eCommerce app development with predictive customer analytics, it’s crucial to accommodate the future system and ML models with vital components. This approach helps leverage benefits of analytics in customer service throughout the entire process, from the moment they discover the brand, through the purchasing process, and on to long-term loyalty. In this manner, businesses can create meaningful interactions at each stage and build stronger relationships.
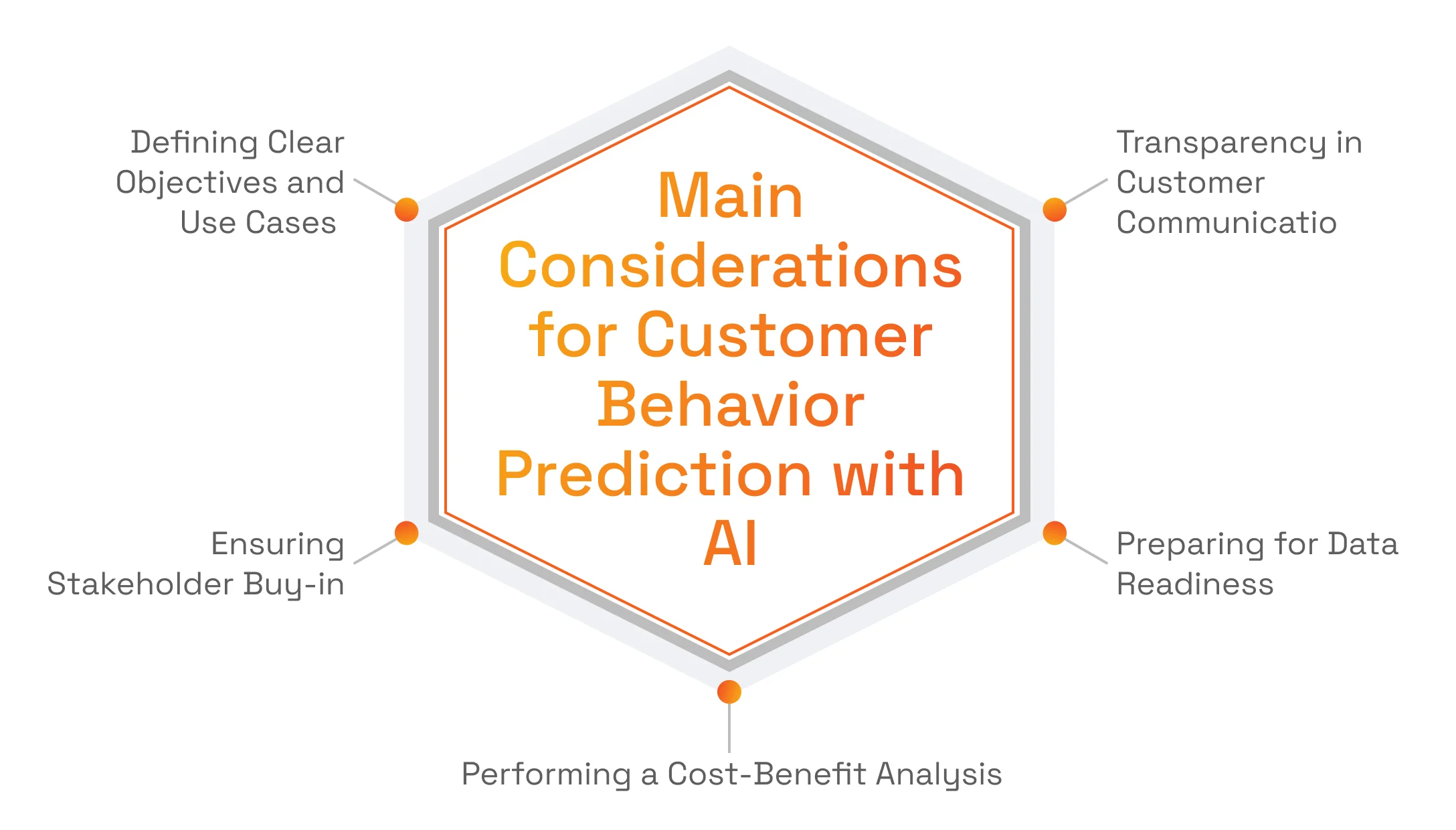
Defining Clear Objectives and Use Cases
Before integrating deep customer analytics into customer service operations, businesses need to identify what they aim to achieve. This involves defining specific goals, such as reducing cart abandonment rates, improving customer segmentation, or enhancing personalized recommendations, and outlining which use cases will deliver the highest impact. By doing all of this, businesses can set measurable KPIs and focus on deploying solutions that directly address customer service challenges at each stage of the buyer’s journey.
Equally important is ensuring that the chosen use cases are both realistic and scalable. Companies should evaluate whether they have the necessary data, technological infrastructure, and internal expertise to support AI customer behavior analysis in each specific area.
Ensuring Business Alignment and Stakeholder Buy-in
Rather than treating behavior prediction projects as isolated tech experiments, companies should integrate them into their customer service vision. This approach guarantees that each predictive solution contributes to broader performance metrics like revenue growth, customer satisfaction, and brand loyalty. In such a way, businesses not only establish clear success benchmarks but also create a seamless collaboration process among departments.
Getting support from stakeholders is equally vital. The resources and long-term vision required for the project’s success are provided by executive sponsorship. A proactive approach to communicating the advantages and possible effects, along with early successes that highlight the worth of AI efforts, eliminates worries and provides more support.
Performing a Cost-Benefit Analysis
With analytics, customer experience improvements involve both upfront and ongoing expenses. This refers to investing in data collection and processing tools as well as hiring specialized talent and providing continuous training. A thorough cost-benefit analysis helps stakeholders assess whether the anticipated gains are worth budget allocations.
To conduct a cost-benefit analysis, companies can start by defining the specific objectives of initiatives for customer behavior analysis with AI and pinpointing the direct and indirect costs involved (e.g. technology investments, data management expenses, and specialized staffing requirements). Next, decision-makers need to estimate the potential benefits along with any intangible gains (for example, the benefit of enhanced brand reputation often comes with improved retention rates). Finally, considering the broader context (e.g. market trends, competitive dynamics, and organizational readiness) must be done to ensure the projected returns justify the investment.
Preparing for Data Readiness
Consumer behavior predictions heavily rely on data. However, according to Gartner, 63% of organizations either do not have or are unsure if they have the right data management practices for AI. To properly forecast behavior, the training data for the model must be extremely relevant to the particular consumer action. Inaccurate forecasts may result from the model becoming confused because of poor data quality. The data accuracy needs to be ensured before the model is built by assessing its availability, quality, and completeness.
Two things can be done for such an assessment. First, you make sure that the necessary data sources are available for the utilization by the model. Second, you ensure that the process of data collection is aimed at capturing the relevant information about customers and their behavior.
Maintaining Transparency in Customer Communication
Customer behavior prediction in eCommerce is indeed a powerful tool, but since it involves the collection of tons of data, customers raise concerns about their privacy. You can build more trust by clearly explaining why, how, and what data is gathered, and by showing how it improves the customer journey, for example, by enabling better recommendations and more relevant offers. Make sure your online store also provides concise privacy policies to protect sensitive data, opt-in/opt-out options, and easy ways for shoppers to share customer feedback about data use.
In addition, retailers can enhance support with AI by improving customer service interactions, for instance, using AI chatbots to answer questions 24/7 and recommend products based on past purchases. This creates more convenient, personalized experiences that strengthen trust and can increase customer loyalty over time.
Our Experience-Based Examples of Predictive AI Implementation Challenges
Even with thorough preparation for AI integration into eCommerce platforms, some challenges can still arise. From our experience, they are, fortunately, possible to overcome. Below we list the most common examples of predictive AI implementation challenges and ways to approach their resolution.
Aggregating Data from Various Sources
The importance of data integration in predictive AI implementation cannot be overstated since companies often source customer information from dozens of channels. This data comes in different formats and can have duplicate records or fragmented insights. Such incomplete or inaccurate data can compromise the accuracy of predictive models and offer incorrect decisions.
When we encounter this challenge, overcoming it requires us both clear processes and robust technology, namely:
- Using data validation and cleansing techniques to remove duplicates, correct errors, and fill in missing values.
- Implementing modern data architecture solutions like data lakes vs data warehouses for consolidating information from diverse sources.
Ensuring Data Governance and Compliance
When it comes to regulated sectors, and eCommerce is one of them, it is important to establish data governance and comply with regulatory requirements. Yet, this is considered one of the major challenges that needs to be addressed for AI projects. The growing market size of data governance reflects this rising concern: the data governance market stood at USD 4.60 billion in 2026 and is projected to reach USD 9.68 billion by 2031, growing at a 16.05% CAGR.
Our experience in implementing data security frameworks, such as PCI DSS, OFAC, HIPAA, and GDPR, helps us to uphold data privacy and security standards throughout the data lifecycle in projects for our clients. To help businesses uphold data privacy and security standards throughout the data lifecycle, our team prioritizes:
- Integrating of advanced encryption protocols and anonymization techniques to minimize the risk of unauthorized access or data breaches.
- Establishing clear permissions and authentication systems to guarantee that only authorized personnel can access sensitive information.
- Leveraging tools that continuously scan data repositories and transaction logs for compliance infractions and flag potential risks.
Building Scalable Infrastructure
Deloitte research shows that in 2025, AI already accounts for a majority of IT budgets at many companies, with significant year-over-year increases driven by both business and IT demand, making scalable infrastructure a prerequisite for any organization building customer behavior prediction systems. However, the same report also shows that infrastructure readiness is low. Handling enormous volumes of client data, creating and refining intricate prediction models, and providing real-time customisation all depend on a strong infrastructure. If businesses can not ensure robust servers with high capacity, they may not be able to establish AI processes, especially when they are wondering how to build a marketplace, where scaling is inevitable.
From our experience, the following measures help us to build scalable infrastructures and ensure possibilities for business growth:
- Leveraging the benefits of cloud infrastructure that automatically adjust compute and storage resources based on demand.
- Utilizing containerization and microservices to break down monolithic applications into smaller, independent services that can be scaled individually.
- Implementing load balancing to distribute incoming requests across multiple servers and optimize performance.
- Using caching and content delivery networks to reduce load on infrastructure by storing frequently accessed data closer to end users.
- Streamlining with DevOps and CI/CD to continuously integrate, test, and deploy updates and quickly address performance bottlenecks.
Serhii Leleko
AI&ML Engineer at SPD Technology
“Cloud or serverless infrastructure, secure data storage, seamless platform integration, and robust security measures are all crucial to accommodate the computational and storage requirements of AI customer behavior analysis. By addressing these infrastructure needs, digital stores can unlock valuable insights from their data, personalize the customer journey, and ultimately drive business success.”
Choosing and Training Appropriate Predictive Models
Another challenge frequently highlighted in AI analytics examples lies in selecting and refining the right predictive models. With numerous algorithms available, determining the optimal solution depends on factors such as data complexity, volume, and desired outcomes. Moreover, once a model is chosen, it requires substantial training, hyperparameter tuning, and validation to achieve high accuracy and minimize bias.
To navigate this complex process, our team leverages its technical expertise and a clear understanding of the specific business context to:
- Conduct pilot projects to compare multiple algorithms and evaluate their performance.
- Utilize AutoML tools to navigate model selection, hyperparameter tuning, and performance measurement without specialized data science expertise.
- Establish validation mechanisms (e.g. cross-validation and holdout sets) to detect overfitting.
Processing and Analyzing Data in Real-Time
Strategies that use analytics for customer retention and acquisition often depend on the ability to provide immediate responses. However, real-time data processing can be particularly challenging, as it involves rapidly collecting, cleaning, and analyzing streams of information.
To help businesses meet these time-sensitive demands, we opt for:
- Adopting stream processing frameworks to handle continuous data ingestion and real-time analytics efficiently.
- Invest in in-memory data grids to maintain frequently accessed data in memory for quick reads and writes.
- Using low-latency databases designed for rapid inserts, updates, and queries under high-traffic conditions.
- Designing for horizontal scalability to distribute workloads across multiple servers or nodes to handle sudden spikes in data volume.
- Embedding real-time monitoring to track system performance and data quality in real time.
If you are willing to know how artificial intelligence transforms customer services, read our dedicated article on this topic!
Why Implementing Predictive Analytics Customer Experience Requires a Pro Approach
AI and machine learning that power predictive customer behavior analysis platforms are complex to design and deploy due to the need for well-structured data, rigorous model calibration, strong data security practices, and often an overhaul of existing infrastructure. All of this requires specialized expertise that many eCommerce companies don’t have in-house.
Teaming up with a seasoned tech vendor can help businesses embrace these innovations. With the right partner, eCommerce businesses not only can get access to the advantages of strategic technology consulting but also technical expertise needed for successful predictive analytics implementation, so they can apply insights across the customer journey, optimize pricing strategies, and strengthen customer loyalty while maintaining robust data governance.
Such partnership can provide companies with:
- Accurate Data Interpretation for Reliable Predictions: A tech vendor can provide expert data analysis for predictive models to rely on the quality and clarity of the data they use.
- Seamless Integration with Existing Systems: An experienced partner can align analytics technical requirements with a company’s current infrastructure for their AI-driven systems to function effectively.
- Customization to Fit Business Goals and Industry Needs: Tech companies can provide a tailored approach for AI implementation that enhances relevance to specific business requirements.
- Ongoing Optimization for Continuous Improvement: A tech partner ensures that AI-driven systems follow the customer analytics trends, the technology remains accurate and effective, and business aims for long-term growth.
Partner with SPD Technology for Predictive Customer Service Solution Implementation
We helped dozens of our clients operating in the eCommerce sector to enhance their platforms with AI consumer behavior analytics. If a business needs us to deliver a similar project, we will bring to the table the following:
- Expertise in AI and Machine Learning: Our team brings deep technical knowledge across a variety of AI and ML frameworks, ensuring each solution is optimized for real-world demands in terms of consumer behavior analysis.
- Comprehensive Data Engineering and Management: From setting up robust data pipelines to refining data quality, we provide end-to-end support for generative practical insights into consumer demand and shopping trends.
- Robust Security and Compliance Measures: We know how to adhere to industry-leading protocols (PCI DSS, GDPR, and more) to protect sensitive customer information.
- Proven Success in eCommerce and Retail: With a track record of delivering impactful solutions for online retailers, our professionals understand how to effectively analyze customer behavior without disrupting existing operations.
How AI Predicts Consumer Behavior for Retention: SPD Technology’s Successful Project
We share a notable example of how we leveraged analytics, AI, and machine learning to help our eCommerce client with customer retention.
Creating an AI-Powered Chatbot for a B2C Fashion eCommerce Brand
A France-based fashion retailer sought to streamline customer service by automating a significant portion of its support operations.
Business Challenge
The client needed an AI-powered chatbot that could provide high-speed responses without overwhelming human agents, yet still integrate seamlessly with their existing web infrastructure. Additionally, the solution had to handle peak traffic periods, while maintaining excellent performance.
SPD Technology’s Approach
Our team designed and implemented a chatbot architecture leveraging a LangChain agent powered by Mistral LLM, with Retrieval Augmented Generation (RAG) for fetching relevant information. To create a unified data format, our engineers parsed, gathered, and stored website content in a vector database built on PostgreSQL and deployed on AWS, enabling fast and precise information retrieval.
Next, the chatbot was fine-tuned to ensure accuracy, using guardrails and prompt engineering to avoid incomplete or incorrect responses. This process required us to test with black-box methodologies and the RAG Triad method. Finally, scalability was addressed by deploying the chatbot on EC2 instances with Kubernetes scripts, allowing the system to automatically scale up or down based on real-time demand.
Value Delivered
Our efforts enabled the client to elevate customer support performance and user satisfaction. Key results include:
- Latency P99 <10s: The chatbot delivers responses within 10 seconds for 99% of user queries.
- Uptime 100% During Peak Hours of 30 Requests Per Second: The system remains fully operational even under heavy traffic.

Key Takeaways
- CPG and retail companies that lead in digital and AI show three times greater total shareholder returns than peers, according to McKinsey, and predictive customer analytics is one of the core drivers of this gap by turning behavioral data into real-time pricing, retention, and demand decisions.
- Generative AI combined with predictive analytics is poised to unlock $240-390 billion in economic value for retailers, but capturing this value requires applying AI across the full customer journey.
- 63% of organizations either lack or are unsure they have the right data management practices for AI, according to Gartner, and through 2026, Gartner predicts 60% of AI projects unsupported by AI-ready data will be abandoned before delivering value.
- Choosing the wrong predictive model for the use case reduces accuracy and increases costs: decision trees suit customer segmentation, random forests suit churn prediction, and neural networks suit real-time purchase intent.
- The data governance market is growing from USD 4.60 billion in 2026 to USD 9.68 billion by 2031, driven by AI regulation and the need for explainable data lineage, reflecting that compliance infrastructure is becoming as critical as model accuracy for eCommerce AI deployments.
In short: predictive customer analytics delivers measurable revenue and retention gains, but only when data quality, model selection, compliance architecture, and scalable infrastructure are treated as core requirements.
FAQ
How much does building an AI customer behavior analysis system cost?
Costs range from $20,000-$80,000 for a focused single-use-case implementation (churn prediction or product recommendations) using pre-trained models and cloud infrastructure, up to $500,000-$2,000,000+ for a fully custom system with proprietary data pipelines, real-time processing, and multiple prediction models.
Mid-market eCommerce businesses typically invest $100,000-$300,000 for a production-ready system covering segmentation, personalization, and demand forecasting. Ongoing costs, which can include cloud compute, model retraining, and maintenance, add 20-35% of the initial build cost annually.
The largest cost driver is data readiness: companies with fragmented or low-quality data spend 40-60% of the total budget on data engineering before a single model is trained.
What data is required to train a customer behavior AI model effectively?
Effective customer behavior models require four core data types: transactional data (purchase history, order value, frequency), behavioral data (clickstreams, session duration, search queries, abandoned carts), demographic data (age, location, device type), and engagement data (email open rates, social media interactions, customer service history). A minimum of 12-24 months of historical data is typically needed to capture seasonal patterns. Real-time prediction systems additionally require streaming data infrastructure to ingest and process behavioral signals within milliseconds of customer interactions.
What are the privacy and compliance risks of AI-based customer tracking?
The primary risks are:
- GDPR violations in the EU (fines up to 4% of global annual turnover);
- CCPA non-compliance in California;
- FTC enforcement in the US for unfair or deceptive data practices.
Specific AI risks include processing behavioral data without explicit consent, using sensitive inferred attributes (health, ethnicity, financial status) for targeting without disclosure, and retaining raw behavioral data longer than declared retention policies allow. Predictive models trained on biased historical data can produce discriminatory outputs, for example, systematically under-serving certain demographic segments, creating both regulatory and reputational exposure.
How long does it take to see measurable results from AI customer behavior analysis?
The timeline depends on use case complexity and data readiness.
- Fraud detection and abandoned cart recovery typically show measurable lift within 4-8 weeks of deployment because feedback loops are immediate.
- Churn prediction models require 2-3 months to validate because the outcome (a customer leaving) takes time to observe.
- Personalization engines delivering recommendations show conversion rate improvements within 6-10 weeks, but full revenue impact takes 3-6 months to stabilize as models learn from real user interactions.
- Full-stack implementations covering segmentation, dynamic pricing, and retention see compounding returns after 6-12 months, when models have accumulated enough live behavioral data to outperform rule-based baselines by a meaningful margin.
What are the most common mistakes companies make when implementing customer behavior AI?
The five most common mistakes are:
- Starting model development before data quality is validated, which produces unreliable predictions that erode trust in the system;
- Selecting a model architecture based on technical preference rather than business use case, for example applying neural networks to problems where a decision tree would be more interpretable and easier to act on;
- Treating the model as a one-time build rather than a continuously retrained system, causing accuracy to degrade as customer behavior shifts;
- Failing to connect model outputs to operational workflows, so predictions exist in dashboards but never trigger actual marketing or merchandising decisions;
- Underestimating change management, since business teams that do not understand how predictions are generated are unlikely to act on them, making organizational adoption as critical as technical accuracy.
What are the best AI tools for customer behavior prediction?
Top AI tools for customer behavior prediction include platforms like Google Analytics, Adobe Experience Cloud, and Salesforce Einstein Analytics. These use machine learning to support customer behavior analysis through web traffic insights, customer journey mapping, and personalized recommendations. The resulting insights can refine marketing strategies and help teams meet customer expectations, especially when combined with ongoing market research and customer feedback.
What are real-life examples of AI in predictive analytics for customer insights?
Real-life examples include Netflix’s personalized movie recommendations, Amazon’s “Customers who bought this also bought…” features, and Sephora’s virtual try-on apps. These solutions rely on AI-powered customer behavior analysis to analyze past actions and predict future preferences, helping brands meet customer expectations with more relevant suggestions. Insights from this kind of analysis can also support personalized marketing campaigns and complement ongoing market research, ultimately enhancing user experience and driving sales.
Are AI-based predictions more reliable than traditional analytics?
Generally, yes. AI-based predictions, powered by ML, can process vast, complex, and unstructured data in real-time and identify subtle patterns traditional methods miss. They learn and adapt, which results in more accurate and dynamic forecasts, especially in volatile environments.
For example, AI models can ingest signals from social media platforms, including social media posts, mentions, engagement, and sentiment, in near real time to detect emerging shifts in customer preferences. These insights can then inform personalized marketing campaigns, revealing patterns that traditional, dashboard-based analytics may capture only after sales data lags behind.