

Since data-intensive technologies become increasingly in demand, global data center spending is projected to surpass $788 billion in 2026, growing 55.8% year-over-year, according to Gartner’s latest IT spending forecast. This staggering number means that organizations are willing to collect, store, process, share, and analyze data in a well-structured manner to further use it for making crucial business decisions.
For this, data infrastructure and analytics are crucial: infrastructure ensures that data is accessible, accurate, secure, and scalable, and analytics tools layered on top of this infrastructure allow businesses to identify trends, optimize operations, personalize experiences, and innovate. In this article, we dive into the role and nuances of these two technologies.
What Is Data Infrastructure?
The business impact of Big Data becomes more evident each day, as companies can get valuable insights from it. However, to do so, businesses, no matter large or small, require infrastructure for Big Data analytics because it helps to make data complete, reliable, and organized. We offer you the following concise data infrastructure definition to better understand what it is.
Data Infrastructure Definition
To answer the question, “What is data infrastructure?”, we need to imagine a framework of multiple components, processes, and technologies that are interconnected and work together. This fusion provides resources for data collection, storage, processing, analysis, and other functions required for data analytics.
Data Infrastructure Examples
The best way to understand data infrastructure is to look at its examples. This table provides a concise overview of data infrastructure examples and their primary use cases.
Infrastructure Type | Best For | Key Advantages | Key Limitations | Example Providers / Technologies |
|---|---|---|---|---|
Traditional On-Premise | Strict data sovereignty needs, legacy systems, predictable workloads | Full hardware and data control, no third-party dependency | High upfront costs, limited scalability, requires in-house IT staff | Dell PowerEdge, HPE ProLiant, Cisco UCS |
Cloud | Cost-efficient scaling, global accessibility, minimal hardware management | Pay-as-you-go pricing, built-in redundancy, fast resource provisioning | Ongoing costs can accumulate, less direct control, data residency concerns | AWS, Microsoft Azure, Google Cloud |
Hybrid | Balancing regulatory requirements with cloud scalability | Flexible workload placement, compliance-friendly, scales on demand | Higher architectural complexity, integration overhead between environments | Azure Arc, AWS Outposts, Google Anthos |
Converged / Hyper-Converged (HCI) | Simplified IT management, VDI, rapid deployment | Reduced hardware footprint, easy to deploy and manage | Vendor lock-in risk, scaling requires adding full nodes | Nutanix, VMware vSAN, Dell VxRail |
Edge | IoT, manufacturing, retail, any use case requiring ultra-low latency | Real-time local processing, reduced bandwidth costs | Limited local capacity, complex to manage across distributed sites | AWS Wavelength, Azure IoT Edge, NVIDIA Jetson |
Infrastructure Type
Traditional On-Premise
Cloud
Hybrid
Converged / Hyper-Converged (HCI)
Edge
Best For
Strict data sovereignty needs, legacy systems, predictable workloads
Cost-efficient scaling, global accessibility, minimal hardware management
Balancing regulatory requirements with cloud scalability
Simplified IT management, VDI, rapid deployment
IoT, manufacturing, retail, any use case requiring ultra-low latency
Key Advantages
Full hardware and data control, no third-party dependency
Pay-as-you-go pricing, built-in redundancy, fast resource provisioning
Flexible workload placement, compliance-friendly, scales on demand
Reduced hardware footprint, easy to deploy and manage
Real-time local processing, reduced bandwidth costs
Key Limitations
High upfront costs, limited scalability, requires in-house IT staff
Ongoing costs can accumulate, less direct control, data residency concerns
Higher architectural complexity, integration overhead between environments
Vendor lock-in risk, scaling requires adding full nodes
Limited local capacity, complex to manage across distributed sites
Example Providers / Technologies
Dell PowerEdge, HPE ProLiant, Cisco UCS
AWS, Microsoft Azure, Google Cloud
Azure Arc, AWS Outposts, Google Anthos
Nutanix, VMware vSAN, Dell VxRail
AWS Wavelength, Azure IoT Edge, NVIDIA Jetson
The following sections delve deeper into each of these examples.
Traditional On-Premise Infrastructure
If one has some understanding of what data infrastructure is, it is most likely they imagine a traditional one. This model involves organizations owning and managing their own servers, storage, and networking hardware in a physical data center or server room on-site.
Cloud Data Infrastructure
In contrast to on-premise infrastructure, cloud computing is fully offered by cloud service providers like AWS, Azure, or Google Cloud. This type involves computing, storage, networking, and security on-demand and online. The best parts about choosing cloud data infrastructure are its high availability since it offers robust redundancy and failover solutions and lower upfront costs since hardware investments are offloaded to the cloud provider.
Hybrid Infrastructure
As the name suggests, this type of infrastructure combines on-premise and cloud characteristics. It allows organizations to keep some workloads or data in their own data center while using cloud services for other workloads. It is especially suited for sharing storage between sensitive and general data: regulated data is best to remain on-premises, while less sensitive information can move to the cloud.
Converged and Hyper-Converged Infrastructure (HCI)
HCI is one of the digital infrastructure examples that goes one step further and groups compute, storage, networking, and other resources into integrated solutions. These solutions are typically sold as a single, pre-validated unit and deliver resources through a software-defined approach on commodity hardware.
Edge Infrastructure
This is one of the data infrastructure examples that implies locating data physically closer to where the data is generated (e.g., sensors, devices, or local servers at remote sites) rather than in a centralized data center or the cloud. It is common in IoT deployments, manufacturing, retail, and other areas requiring immediate feedback loops.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“While each type serves its unique purpose, cloud infrastructure is the most commonly used nowadays due to cost-efficiency. Most cloud providers offer a pay-as-you-go model and do not require large upfront investments in hardware. Yet, the hybrid type comes as the second practical choice in case a business wants to secure some of their data.”
Data Infrastructure Components, Processes and Technologies
Big Data infrastructure is a complex system consisting of data lakes or warehouses, metadata, databases, server, and multiple other components, processes, and tools. To make sense of it, below are the main elements of an infrastructure.
Hardware and Software Components
For organizations to be able to store, manipulate, and process data, the infrastructure must have specific tools and processing power.
1. Software Solutions for Data Storage
The following components are responsible for managing data and documenting its context.
Infrastructure Database
Database serves as a data ecosystem within an organization. It can contain one or a set of databases (relational or NoSQL) that are used for critical applications. The infrastructure database handles real-time data manipulations and feeds data to data repositories and analytics tools.
Data Lakes and Data Warehouses
Lakes and warehouses are repositories that take data from databases. The difference between data warehouses and lakes is that the former stores structured data, while the latter deals with unstructured data.
Data warehouse design implies predefined schemas, making them ideal for business intelligence (BI). Data lakes, in turn, are known for storing data with minimal processing or schema enforcement. This is why they are a preferred choice when businesses need data science experiments, machine learning pipelines, and scenarios where a schema-on-read approach is beneficial.
Discover the step-by-step process of how to build a data warehouse in our dedicated article.
Metadata Repositories and Data Catalogs
These are the tools or systems where the company stores its information about data lineage, ownership, definitions, and relationships. Metadata repositories and data catalogs are important for two reasons: they make sure that the data stored within a company has clear definitions, and they ensure that this data uses lineage tracking. Thus, all users can easily find the data they need for analytics or reporting.
Analytics Dashboards
Dashboards are visual interfaces that present processed and assembled data in charts, graphs, and tables. They serve as representations of key information, be it KPIs, ROI, or other metrics.
2. Hardware Components
The following components are responsible for storing and running data.
Servers
Servers are integral parts of data storage infrastructure and represent physical or virtual machines that run the software needed to process and store data. They also facilitate the exchange of data between different systems.
Data Centers
Data centers are physical facilities that have numerous equipment for working with data. They serve as a core for computing and storage resources and typically include servers, storage systems, networking equipment, cooling and power management systems, as well as backup generators.
Processes
There are numerous processes happening within a Big Data infrastructure. They make sure that its data is kept in accordance with quality benchmarks, regulatory standards, and governance policies.
Database Infrastructure Design
While database infrastructure itself is a component of data infrastructure, the design of that infrastructure involves a set of decisions and structured activities, which makes it a process.
Database infrastructure design offers a structure for choosing the right database technology (relational, NoSQL, or hybrid), defining its schema, setting up hardware or cloud resources, and establishing performance, security, and scalability requirements. Having the correct design means the right performance and data integrity.
Data Infrastructure Management
This process encompasses several activities that help optimize and monitor the data environment. Data infrastructure management often includes but is not limited to such practices as patching software, updating hardware, and managing capacity demands.
Data Governance Policies
Policies are guidelines that allow organizations to organize their data. This is done by establishing rules for accessing, using, storing, and protecting data across a company. These policies should not be overlooked as they not only allow to maintain high data quality for close-to-perfect analytics results but also ensure regulatory compliance.
Data Infrastructure Technologies
The toolset required for the infrastructure must allow organizations to aggregate and exchange data.
Data Integration Tools
Data infrastructure must come with tools for integration in order to streamline merging data from disparate sources into a unified format. Only with such tools, organizations can prepare data for analytics and reporting as well as the use within an organization.
Integration tools are responsible for:
- Automating Extract-Transform-Load (ETL) or Extract-Load-Transform (ELT) workflows.
- Supporting real-time or near-real-time data streams.
Networking Technologies
Tools for networking enable secure, high-speed connectivity among on-premise servers, cloud platforms, and edge devices. This type of data infrastructure technologies ensures efficient data transfer, minimizes latency, and supports distributed computing requirements.
Core networking technologies components include:
- Routers
- Switches
- Firewalls
- Load balancers
- Network links.
Why a Modern Data Infrastructure is Critical for Enabling Actionable Data Analytics
With a robust infrastructure, big data can be effectively organized, stored, optimized, and processed, which means that it is ready to be analyzed and seen at new angles. Thus, companies can detect certain patterns and trends that highlight important information. Below, we list more benefits of a modern data infrastructure.

- Foundation for Data-Driven Decision Making: Having a data infrastructure means keeping the right resources for aggregating and organizing data in a single centralized place. With such an approach, organizations have access to the data as a whole and can perform its in-depth analysis. This analysis, in turn, leads to uncovering of the information that was hidden in patterns and trends.
- Enhanced Data Accessibility: Since an infrastructure has all the data in one place, all the organization’s stakeholders know where to find the information they need. Moreover, they can have specialized access that makes only relevant data available to them. With such accessibility, it becomes much easier to collaborate across departments and generate analytical outcomes.
- Scalability to Handle Growing Data Volumes: As companies inevitably grow, a solid infrastructure can accommodate this growth with scalability. This means that there will be enough storage and computing capacity to run the same analytical processes in larger volume without compromising performance.
- Improved Data Quality and Integrity: A solid infrastructure provides the possibility for effective data quality management. This means that the company introduces specific data rules that define how to keep data complete, error-free, and relevant. Such rules are designed for assisting companies in automating data cleansing and creating a one core source of truth. All these measures have a positive impact on generated analytical insights, guaranteeing their correctness and relevance.
- Real-Time Data Processing Capabilities: Today’s infrastructures empower organizations with the ability to instantly absorb and dissect data. This translates the information into immediate actions, which are essential for acting on trends and overcoming competition.
- Cost Efficiency and Resource Optimization: Big Data analytics infrastructure may seem costly at first, when setting up resources and buying storage. However, in the long run, it helps streamline data management processes and reduces redundancy. Such an efficient resource utilization makes sure that analytics operations do not require expensive additional resources.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“Apart from the evident benefits of robust infrastructure, it is essential to note that evolving technological advancements in analytics demand more powerful resources. This is the reason why high-performance systems are indispensable for generating advanced insights, particularly through AI and ML.”
Building Data Infrastructure for Advanced Analytics Capabilities Step-by-Step
Building data infrastructure is a process that needs to be approached in several phases, considering multiple components and processes, and requires expertise in advanced tools. Below are common factors that should be taken into account when preparing an analytics infrastructure.

Defining the Business & Analytics Objectives
The first and foundational step is to define what aspect of business data analytics will cover. Businesses may want process optimization, deeper understanding of what customers expect from the company, or looking for new revenue opportunities. No matter the goal, the company’s stakeholders must agree on one or several objectives, since it will help to further define what the company expects to achieve with new data analytics initiatives. Consequently, all the investments into a new infrastructure will be completely justified.
Auditing Existing Data Ecosystem
The systems, databases, and analytical tools that are already in place are a valuable foundation for the future infrastructure. However, to make sure the infrastructure conforms to every requirement data analytical processes may have, it is important to evaluate the data sources, volumes, and complexity of the existing ecosystem. This is a necessary step as it can highlight redundant processes and inefficiencies for the technical team to address and eliminate. As a result of such an audit, companies get the chance to upgrade or replace legacy elements that prevent a data infrastructure platform from performing seamlessly.
Designing a Scalable Data Architecture
When it comes to data architecture, two of the most vital factors to consider should be handling growing data volumes and evolving business needs. For this, companies need to select appropriate storage solutions, like an enterprise data warehouse, choose between on-premise, cloud, or hybrid deployments, and determine how best to integrate streaming or batch processing. Approaching all of these factors beforehand and with careful consideration will guarantee that the company will not make large additional investments in resources in the process.
Building Data Pipelines for Ingestion & Transformation
Pipelines can be considered the lifeblood of data analytics because they are responsible for moving information securely from different sources to a single place. The whole process needs to be gentle with data in order not to corrupt it. This is why these pipelines typically have ETL or ELT processes, as they cleanse, standardize, and enrich data. With these processes in place, as well as automated and set up for real-time workflows, data infrastructure design is considered optimal for reliable data analytics with minimal latency and a continuous flow of up-to-date insights.
Implementing Strong Data Governance & Metadata Management
Even though there is no correct analytics without data governance, Deloitte’s 2025 CDO Survey found that while 51% of CDOs rank data governance as their top priority, 47% say competing organizational priorities hinder their ability to realize the full value of data. This gap can be an actual benefit for organizations that prioritize data governance and metadata management to gain an advantage over competitors. They need to define the rules of how their data is accessed, shared, and maintained across an organization, as well as outline data lineage and definitions to guarantee the management of metadata.
Ensuring Security & Access Controls
No matter if a company builds an enterprise data infrastructure or a smaller one, ensuring its security is essential for keeping intellectual property and customer information safe. This is why encryption at rest and in transit, role-based access, and continuous monitoring for suspicious activity must be prioritized.
Validating Analytical Readiness
Before rolling out analytics solutions, it’s crucial to validate that the data, infrastructure, and tools can support accurate and performant insights. This involves either pilot studies or proof-of-concept projects to check data consistency, system scalability, and query response times. Successful validation provides confidence that the analytics platform will meet both current and anticipated workloads.
Planning for Ongoing Optimization & Scaling
Since the evolution of a business almost always implies growth, companies must take care that available resources are accommodating the data perfectly and do not create performance bottlenecks. Organizations should establish a framework for monitoring performance, which will help to identify new data sources and update data models or tools as new business requirements appear.
Possible Challenges of Setting up a Data Analytics Infrastructure and How SPD Technology Overcomes Them
When companies build data analytics platforms and set up infrastructures for them, they will most likely encounter some challenges. The most common ones are easy to predict and resolve. So, we offer you to review the typical issues and their resolutions.
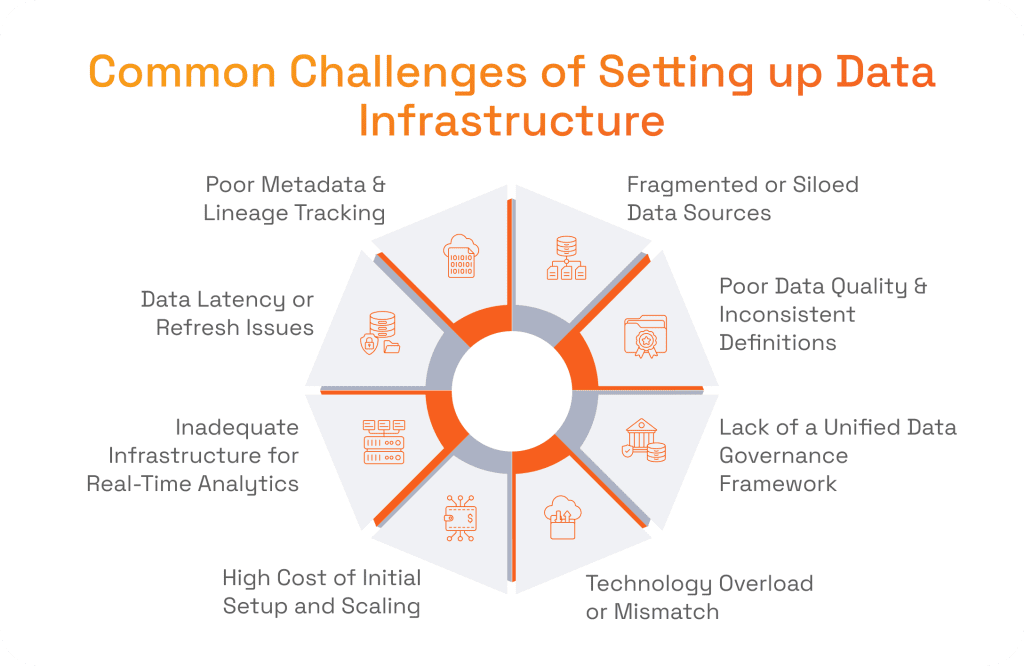
Fragmented or Siloed Data Sources
Gartner research found that 63% of organizations either do not have or are unsure if they have the right data management practices for new technologies, including AI, predicting that through 2026, organizations will abandon 60% of AI projects unsupported by the right data. We can support these statistics with our experience, as we see that our clients often work in multiple ERP platforms, CRM tools, departmental databases, and various SaaS applications, which are not connected to the same repository. As a result, all employees can not use data analytics to their full potential: generated insights end up to be incomplete or duplicated.
We typically overcome silos thanks to:
- Recognizing the importance of data integration (e.g., ETL/ELT pipelines) to unify disparate data sources.
- Using common data models or data warehouses/lakes to centralize data.
- Establishing data-sharing processes, including data catalogs and metadata management.
Poor Data Quality & Inconsistent Definitions
Gartner found out that poor data quality costs companies around $13 million a year on average. At the same time, our clients often report that they have difficulties with validating and cleaning their data without the help of a technical expert. As a result, they cannot fully leverage analytics or encounter misleading analytical results.
To help companies improve data quality, we suggest:
- Establishing data quality standards and automated validation checks.
- Using data profiling tools to identify and remediate errors in source data.
- Having a data management strategy in place to know how to standardize data and keep an eye on its quality.
Explore important criteria to include into an effective data management strategy in our dedicated article!
Lack of a Unified Data Governance Framework
Our clients that are seeking to establish analytical processes often lack a governance framework that must be an integral part of data infrastructure strategy. These companies do not have a clear understanding of ownership, responsibilities, and policies around data usage. Such a lack of governance can result in security breaches and regulatory violations.
In such cases, we typically suggest:
- Defining clear data governance roles (e.g., data stewards and data owners).
- Documenting and enforcing policies for data access, usage, and lifecycle management.
- Aligning governance strategies with relevant regulatory requirements (e.g., GDPR, HIPAA, PCI DSS).
Technology Overload or Mismatch
Some of our clients tried using a number of analytics tools within a company and ended up with inefficiencies. Some features overlapped or did not integrate well with their existing business systems. In the end, they were not satisfied with the outcomes of data analytics, as those were duplicated, complex, or confusing.
When it comes to overload or mismatch of technologies, we offer our clients to:
- Conduct assessments of business requirements before tool selection.
- Consolidate or standardize technologies where practical.
- Consider scalability and integration during vendor evaluations.
High Cost of Initial Setup and Scaling
Hardware, software licenses, and training personnel often require companies to spend a lot of money in the first month of setting up data analytics. Some of our clients had concerns about these investments, making them doubt the adoption of analytics. What’s more, costs can escalate quickly if the infrastructure has to be scaled for large data volumes or for complex real-time analytics.
To help organizations optimize these expenditures, we often offer to:
- Leverage the benefits of cloud computing infrastructure to reduce initial expenses.
- Adopt a modular architecture to expand capacity on demand.
- Prioritize high-impact use cases that can demonstrate early value.
- Utilize open-source technologies and managed services where appropriate.
Inadequate Infrastructure for Real-Time Analytics
Our clients with established businesses often have legacy systems that are not capable of supporting real-time or near real-time capabilities. Their systems are typically built around batch processing models and have limited streaming data ingestion, outdated APIs, and inadequate mechanisms for low-latency data transformations.
The following practices help us to set up data analytics real-time capabilities for our clients:
- Deployment of streaming data platforms (e.g., Kafka) for real-time ingestion.
- Implementation of in-memory processing and optimized data stores for low-latency analytics.
- Usage of distributed compute frameworks that can scale to handle large event streams.
- Implementation of caching strategies to deliver faster insights to end users.
Data Latency or Refresh Issues
There are cases when our clients complain that they missed critical updates or respond too slowly to emerging trends. Yet, they do not know why. After auditing their platforms, we usually find that the reason for that is stale data in their analytics dashboards and reporting systems. This is commonly caused by inefficient data pipelines, batch-only processes, or connectivity issues between data sources and the analytics environment.
To overcome these issues, we offer to:
- Optimize ETL/ELT processes to reduce load times (e.g., through parallelization).
- Introduce micro-batch or streaming approaches where real-time insights are required.
- Monitor and adjust data refresh schedules based on usage patterns and latency needs.
Poor Metadata & Lineage Tracking
A lack of clear metadata and data lineage makes it difficult for our clients to understand where data originates, how it transforms, and how it is used downstream. This is why they often turn to us for help with troubleshooting, root-cause analysis, and regulatory compliance.
To resolve these issues and prevent them from happening in the future, we do the following:
- Implement data cataloging tools that automatically harvest metadata.
- Document end-to-end data lineage, including transformations and user consumption.
- Enforce consistent metadata standards across all data repositories.
- Integrate lineage information into data governance and compliance frameworks.
Why Big Data Infrastructure Engineering Requires a Professional Approach
With a cutting-edge infrastructure, analysis of Big Data becomes increasingly valuable. From experience, many of our clients felt relief when we helped them set up infrastructure and analytics processes, as their internal tech teams were well-versed in their domain tech processes rather than data analytics. Below are more reasons to partner with a professional company:
- Architectural Complexity Demands Deep Expertise: Designing large-scale data platforms involves coordinating distributed systems, security protocols, and data pipelines and requires specialized engineering knowledge. For example, setting up a customer data infrastructure demands deep familiarity with end-to-end architectural principles.
- Mistakes Are Costly at Scale: When dealing with massive data volumes, even small database configuration errors can quickly escalate into major disruptions or financial losses. Proper data infrastructure management processes and robust governance help mitigate risks and maintain service continuity.
- Performance Optimization Requires Engineering Know-How: Handling high-velocity and high-volume workloads efficiently calls for in-depth expertise in query optimization, distributed computing, and IT infrastructure analytics. Only processionals can perform these tasks and help companies achieve the best balance of speed, reliability, and resource utilization.
- Integration with Advanced Analytics Requires a Future-Proof Stack: Adopting cutting-edge tools like real-time analytics engines or ML platforms necessitates flexible systems. An expert tech vendor can provide organizations with data management infrastructure to ensure these advanced technologies are integrated without constant redesigns or unstable environments.
- Cloud Resource Management Must Be Strategic: Rapidly provisioning and scaling cloud-based Big Data infrastructure services or data infrastructure as a service can become expensive if not done correctly. Skilled professionals plan capacity, manage costs, and align resource usage with performance requirements.
- Business Alignment Requires More Than Technical Skill: A truly effective Big Data strategy blends engineering rigor with clear business objectives. Professionals who handle infrastructure data consider not only technical aspects but also organizational goals for long-term growth.
Consider SPD Technology for Big Data Infrastructure Services
Our team has set up data infrastructures for analytics for many companies, and our rich experience helps us navigate the most complex challenges, unique business requirements, and important industry trends. By having us by your side, you gain the advantages of the strategic technology consulting and access to:
- Proven Experience Across Full Data Stack: Our team can help you set up layers for data ingestion, storage (such as data warehouses or lakes), transformation (via ETL/ELT processes), and analytics to convert raw data into insights.
- Delivery of Scalable, Cloud-Native Architectures: Our data analytics services are designed to assist companies in generating insights cost-consciously and with the future growth in mind. This is why we leverage cloud architectures for our clients, yet can also set up on-premise or other solutions if necessary.
- Business-Aligned Data Engineering: We focus on practical use cases and measurable outcomes in data initiatives to ensure that every data solution is directly tied to your overarching business goals and helps your organization optimize ROI.
- Regulatory & Security Expertise: From HIPAA to GDPR, our team understands the importance of safeguarding sensitive information and implements robust security measures, audit trails, and governance frameworks to protect your organization.
- Built-In AI/ML-Ready Architecture: We combine our expertise in data analytics with skills in AI/ML development to support advanced analytics initiatives. With streamlined data pipelines and scalable storage solutions, you can quickly integrate ML models, deploy real-time analytics, and innovate without being held back by technical constraints.
- Cross-Domain Expertise: Having delivered successful projects in multiple sectors, we know how to optimize fraud detection in finance, ensure patient data privacy in healthcare, or boost personalized marketing in eCommerce.
Our Project: Building a Robust Infrastructure for Big Data Analytics in the Construction Industry
We help recognized companies to set the path toward practical and insightful decision-making. Below is one of our numerous success stories.
Accelerating Data Infrastructure & Analytics for HaulHub’s Transportation Construction Platform
HaulHub, a US-based transportation construction company, needed a hand in setting up a unified digital platform that serves agencies, contractors, vendors, and suppliers.
Business Challenge
The client set up the handling of their mission-critical workflows like digital ticketing, field inspections, and real-time project tracking. However, HaulHub also needed assistance scaling its data infrastructure to ingest large volumes of ticket data and integrate advanced AI features. They also faced the challenge of integrating disparate legacy code and ensuring tight security and compliance measures for sensitive construction and transportation data.
SPD Technology’s Approach
Our team started with overhauling the existing agency collaboration component of the entire system by analyzing existing code, implementing robust data pipelines, and optimizing the platform’s data architecture for high-volume loads.
Afterward, we developed mobile and web apps using Java with Quarkus on AWS Lambda, complemented by native iOS/Android builds for peak performance. We applied our data engineering best practices, such as AWS Database Migration Service, ETL tools, and advanced caching, to enable near real-time analytics across tens of millions of ticketing records. We also integrated AI/ML capabilities (OpenAI ChatGPT, AWS Bedrock) to streamline operations like automated reporting, image processing, chatbot interactions, and traffic analysis.
Value Delivered
Our efforts resulted in a feature-rich, AI-powered, and data-driven ecosystem for the transportation construction industry that enabled digital ticketing, automated inspections, and real-time analytics to agencies, contractors, vendors, and suppliers across the United States.

Conclusion
When looking for the answer to “What is a data infrastructure?”, the best way to explain it is to look at its types: cloud, on-premise, hybrid, HCI, and edge. These infrastructures provide the necessary resources to run data analytics processes and consist of software, hardware, processes, and relevant technologies.
Having a modern data analytics infrastructure is important for organizations as it helps to keep optimal data quality, grow and scale processes, and make practical decisions. To set up such an infrastructure, it is important to define requirements for data analytical processes, perform an audit of existing data processes, design scalable data architectures, build data pipelines, implement strong data governance and metadata management measures, ensure security, validate analytical readiness, and plan ongoing optimization.
However, no matter how ready the organization is for data analytics infrastructure setup, some challenges may arise. Those issues can be fragmented data, poor data quality, lack of a unified data governance framework, technology overload, high initial set up cost, inadequate real-time capabilities, data latency, and poor metadata. In order to address these complexities, organizations might need the help of a seasoned tech provider. We know that for a fact because we helped many companies to improve their decision-making processes. You can contact us, and we will help your organization to get the most out of modern data analytics infrastructure and processes.
FAQ
What Is Data Infrastructure and Analytics?
Data infrastructure means having the technologies, architectures, and methodologies for data gathering, storing, processing, and examining. When data infrastructure is in place, it provides the possibility to unlock analysis of that data and derive actionable insights from it.
What Is an Example of a Data Infrastructure?
An example is a cloud-based data warehouse, such as Amazon Redshift, combined with ETL pipelines, analytics tools, and governance frameworks. This technology helps organizations to ingest, store, and analyze massive data sets.
What Is Analytical Infrastructure?
Analytical infrastructure consists of the hardware, software, and processes necessary for critical, advanced data processing, modeling, and reporting, which provides the computational resources to turn data into business intelligence information.
What Are the 4 Components of Data Analytics?
Data analytics typically includes data collection, data storage, data processing, and data presentation, which forms a pipeline that moves information from input to insights for organizational planning.