
The success of a data warehouse depends less on technology selection and more on architectural decisions made early in the project. Data warehouse design creates the blueprint for managing data sources, ETL pipelines, storage structures, security controls, and analytics access. When designed correctly, the warehouse remains scalable, maintainable, and aligned with business goals over time.
Data is the new oil. However, 78% of organizations still struggle to drive business goals with data, and only 57% have complete confidence in its accuracy.
Despite their efforts, only one in three businesses (37%) succeeded in improving data quality in 2023. Flawed data warehouse design is one culprit: it can easily undermine data quality, accuracy, and reliability instead of improving them.
Let us share with you data warehouse design essentials, from its components and architecture types and layers to the key steps in the design process and best practices based on our experience.
Data Warehouse Design: Foundations
Before we dive into the data warehouse architecture layers and design steps, let’s make sure we’re on the same page regarding what data warehouse design is and why it matters.
What Is Data Warehouse Design?
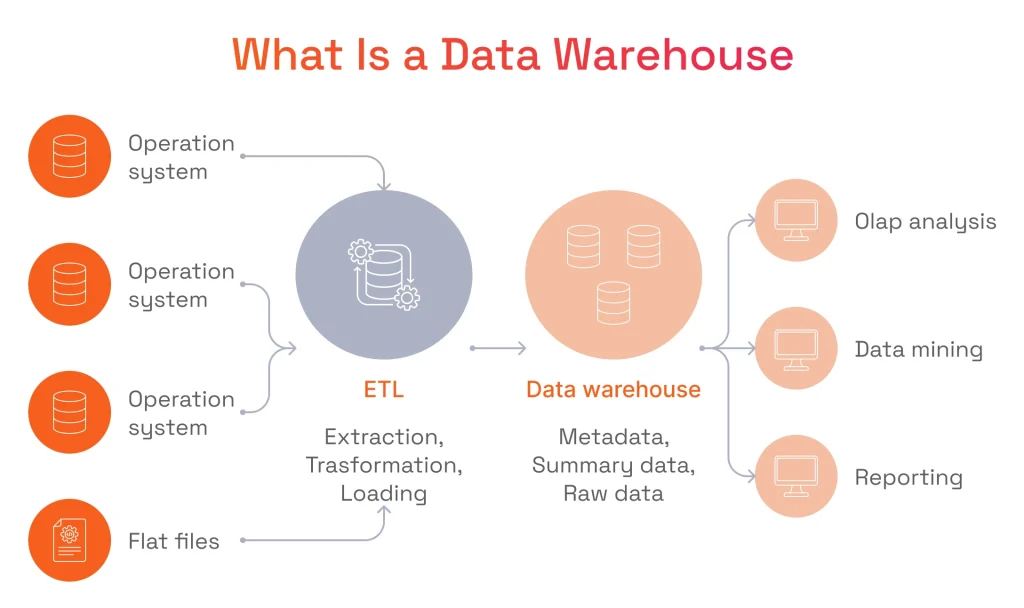
Data warehouse design is the process of structuring the system architecture that would later aggregate petabytes of data from various sources for data mining and analytics purposes.
Here’s how an enterprise data warehouse functions, in broad strokes:
- Collection: The system aggregates data from multiple sources (e.g., HR databases, sales records) via the Extract, Transform, Load (ETL) pipeline. It involves three stages: extracting data from the connected systems, transforming it (cleaning, standardizing, and enriching it), and loading it into the data warehouse for storage.
- Organization: The solution structures data to make it searchable and easy to use, much like you would organize files in folders.
- Access: Business users can view and analyze the stored data using queries, reports, and dashboards to power their decision-making.
How Data Warehouse Design Impacts Your Data Initiatives
Data warehouse design is the foundation for the system’s:
- Performance. Optimized schemas and indexing ensure fast query processing.
- Scalability. Efficient architecture design supports scaling as data volumes grow without deteriorating performance.
- Complex query handling. Well-thought-out data modeling enables complex queries to run efficiently, even if they involve hundreds of data points or petabytes of data.
- Centralized data standardization. Well-designed processes ensure data uniformity, quality, and consistency, minimizing the risk of duplicate or incorrect entries and improving the accuracy of analytical tools’ output.
- Lower operational costs. Proper design minimizes storage and compute resource consumption, mitigating resource waste.
- Maintainability and extendibility. Flexible architecture facilitates maintenance and updates, powering business agility as you can easily adapt the system to new requirements.
- Longevity. Designing the data warehouse architecture properly once means avoiding redesigning or refactoring the system early on.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“Proper data warehouse design is integral to unlocking the full potential of your data while ensuring an optimal TCO, performance, and scalability for the solution itself. It also allows you to foster a truly data-driven culture by making data readily available, easily accessible, and trustworthy.”
Data Warehouse Components
A data warehouse architecture consists of data sources, ETL/ELT processes, the warehouse database, access tools, metadata, data marts, and data management and control tools.
Data Sources
Data sources encompass all the applications, systems, and files that will supply data to the data warehouse. They can include CRM and ERP systems, CSV files, point-of-sale systems, IoT devices, SQL/NoSQL databases, and more. An average company uses 16 data sources in its data warehouse solution.
Extract, Transform, Load (ETL)
ETL tools, as the name suggests, extract, transform, and load data from multiple sources into the data warehouse. ETL processes are essential in consolidating data and cleansing, standardizing, and preparing it for further use (analysis, querying, etc.).
The Extract, Load, Transform (ELT) process is an alternative to the ETL pipeline. It means that data transformation takes place after it’s loaded into the warehouse.
Warehouse Database
This is where all the collected data is loaded and stored after cleansing and transformation, enabling users to access it via queries. Amazon Redshift and Azure SQL are two examples of solutions that power cloud-based warehouse databases.
Data Warehouse Design Patterns
Star and snowflake schemas are two common data warehouse design patterns to optimize the database for better query performance and scalability.
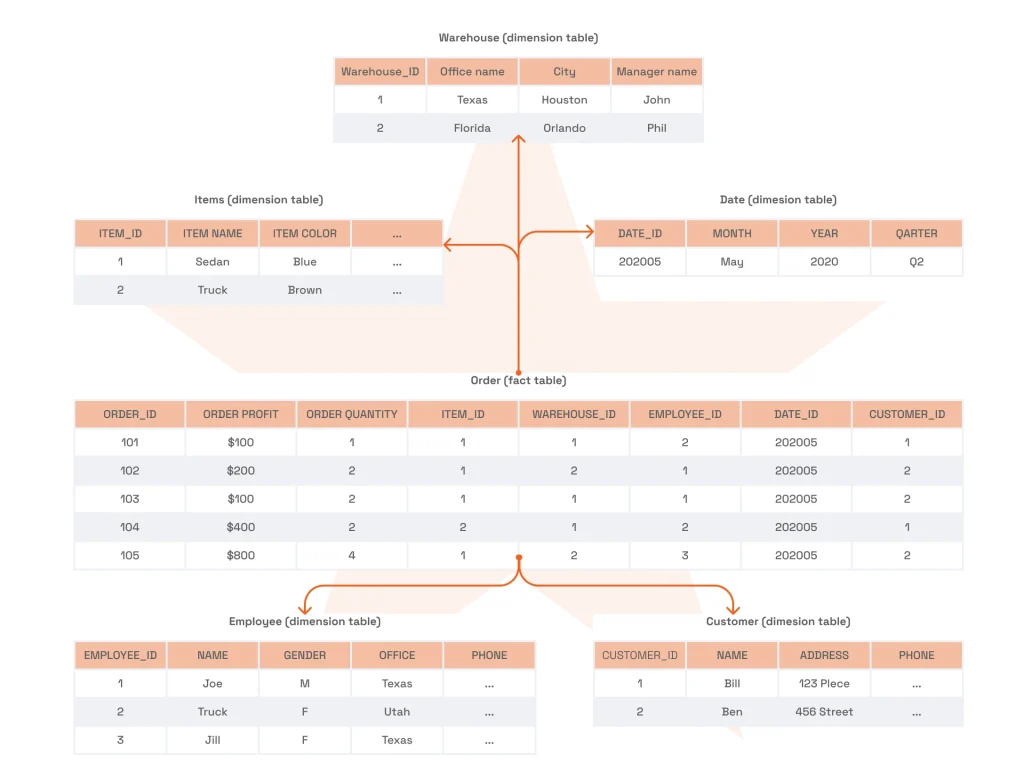
The star schema consolidates all data in a single fact table, which is then linked to denormalized dimension tables. Its advantages include simplicity and high query performance. However, they come at the price of higher data redundancy.
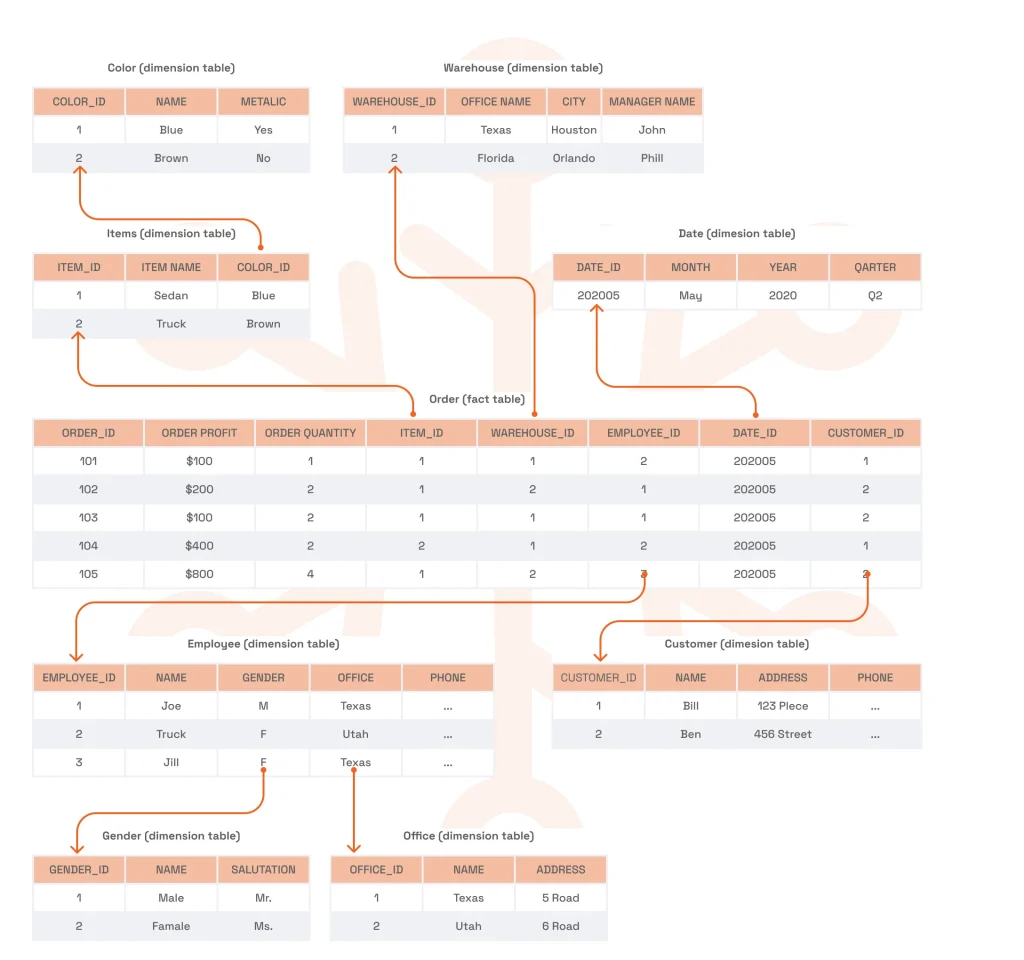
Under the snowflake schema, the fact table is connected to normalized dimension tables, which have their own child tables. This schema is less common as query performance may suffer. In return, however, you get lower data redundancy under this schema.
Access Tools
These tools enable business users to access collected and stored data with analytics, visualization, and reporting capabilities. Common access tools include:
- Query and reporting tools
- Application development tools
- Data mining tools
- Online analytical processing (OLAP) tools.
Metadata
Metadata describes the data itself, providing context regarding its source, storage, handling, and use. It also makes data searchable. For example, metadata can include information about the item’s author, location, size, and last modified date.
Data Marts
A data mart is a subset of the data warehouse that caters to the needs of a specific business function or line of business. Data marts enable users to quickly gain access to data and analytics relevant to their function, without searching the whole data warehouse.
Data Management and Control Components
These components allow your team to add, remove, and manage data sources, access controls, user authentication and authorization, and data encryption. They also enable robust data governance in accordance with regulatory requirements.
The components described above serve different functions within the warehouse ecosystem, but they ultimately work together to move data from operational systems to business users. Understanding how these pieces interact makes it easier to evaluate architecture decisions and identify potential bottlenecks before implementation begins.
Component | Primary Purpose | Key Responsibilities | Business Value |
|---|---|---|---|
Data sources | Supply raw data to the warehouse | Provide operational, transactional, and external data | Centralized access to enterprise information |
ETL/ELT processes | Move and transform data | Extraction, cleansing, validation, transformation, loading | Consistent and analytics-ready data |
Warehouse database | Store integrated enterprise data | Data storage, indexing, optimization, retrieval | Reliable analytics foundation |
Data models | Organize relationships between data entities | Fact and dimension design, schema optimization | Better query performance and usability |
Access tools | Enable analytics and reporting | Dashboards, reporting, ad hoc analysis, BI access | Faster decision-making |
Metadata | Provide context about data assets | Definitions, lineage, ownership, quality information | Improved governance and trust |
Data marts | Deliver subject-specific views of data | Departmental or domain-focused analytics | Faster access to relevant business insights |
Governance and control components | Ensure security and compliance | Access controls, monitoring, policies, auditing | Reduced risk and stronger compliance |
Component
Data sources
ETL/ELT processes
Warehouse database
Data models
Access tools
Metadata
Data marts
Governance and control components
Primary Purpose
Supply raw data to the warehouse
Move and transform data
Store integrated enterprise data
Organize relationships between data entities
Enable analytics and reporting
Provide context about data assets
Deliver subject-specific views of data
Ensure security and compliance
Key Responsibilities
Provide operational, transactional, and external data
Extraction, cleansing, validation, transformation, loading
Data storage, indexing, optimization, retrieval
Fact and dimension design, schema optimization
Dashboards, reporting, ad hoc analysis, BI access
Definitions, lineage, ownership, quality information
Departmental or domain-focused analytics
Access controls, monitoring, policies, auditing
Business Value
Centralized access to enterprise information
Consistent and analytics-ready data
Reliable analytics foundation
Better query performance and usability
Faster decision-making
Improved governance and trust
Faster access to relevant business insights
Reduced risk and stronger compliance
Data Warehouse Architecture
The components described above are organized in layers within the data warehouse architecture. However, their exact distribution depends on the architecture type. So, let’s break down the common data warehouse architecture types and key layers to further understand how to design a data warehouse.
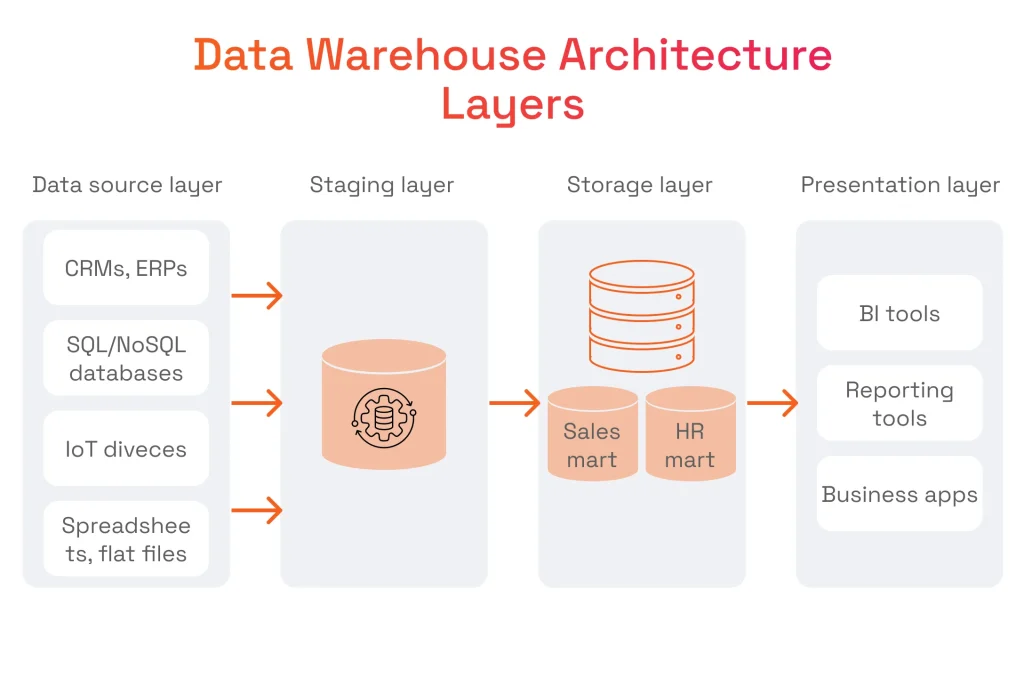
An enterprise data warehouse architecture can be broken down into four layers: source, staging, storage, and presentation.
Source Layer
This layer encompasses all data sources that will feed the data to the warehouse. This is also where the exact phase of the ETL/ELT pipeline takes place. Extracted Big Data can include both structured (JSON, XML) and unstructured types (text, multimedia files) from connected databases, file systems, and software systems.
Staging Layer
After the data is extracted, it can be either loaded into the warehouse and then transformed (ELT pipeline) or transformed and then loaded (ETL). The data is transformed in the staging layer to ensure its adherence to standardization rules, integrity, consistency, and quality. Transformations involve cleansing, conversion, enrichment, and more.
Common tools for this layer include Apache Spark, AWS Glue, Data Build Tool (DBT), and Talend.
Data Storage Layer
The extracted and transformed data is loaded into the storage layer, powered by solutions like Amazon Redshift, Snowflake, or Microsoft Azure Synapse. This layer hosts the data and makes it available for analysis by the presentation layer tools. Data marts are part of the data storage layer.
Presentation Layer
This layer is home to business intelligence (BI) tools like Tableau, Power BI, and Qlik. It enables users to access data via easy-to-grasp mediums like reports and dashboards and run data analytics algorithms. OLAP tools can be added to this layer to power complex queries and multidimensional analytics for large datasets.
Interested in building a data warehouse?
Our experts prepared a comprehensive guide on how to do it right for you.
Types of Data Warehouse Architecture
After we became familiar with data warehouse architecture layers, it’s essential to understand that they can be distributed differently, depending on the type of architecture itself:
- Three-tier architecture: The system consists of three layers: data source, data warehouse, and presentation layers. It offers a clear separation between data extraction, storage, and user access. It’s the most common architecture type as it powers better data quality, scalability, and ETL; however, it is more complex to implement and manage.
- Two-tier architecture: It combines the warehouse database and presentation layers in one tier and puts data sources in the other. This architecture is simpler to implement, making it more suitable for smaller organizations with run-of-the-mill data needs.
- Hub-and-spoke architecture: The data warehouse serves as a central hub that provides data to multiple data marts (spokes). This architecture type satisfies a variety of specific business needs while preserving data management consistency.
Architecture choices influence scalability, maintenance effort, integration complexity, and reporting performance. The models discussed above are designed for different operational needs, making the choice of architecture one of the most important decisions in a data warehouse project.
Architecture Type | Structure | Advantages | Limitations | Best Suited For |
|---|---|---|---|---|
Three-tier | Data source, warehouse, and presentation layers separated | High scalability, strong governance, better performance | More complex implementation and maintenance | Large enterprises and complex analytics environments |
Two-tier | Data warehouse and presentation layers combined | Simpler architecture and faster deployment | Reduced scalability and flexibility | Smaller organizations and less complex reporting needs |
Hub-and-spoke | Central warehouse connected to multiple data marts | Department-specific analytics with centralized governance | More complex data management | Organizations with diverse business units and reporting requirements |
Architecture Type
Three-tier
Two-tier
Hub-and-spoke
Structure
Data source, warehouse, and presentation layers separated
Data warehouse and presentation layers combined
Central warehouse connected to multiple data marts
Advantages
High scalability, strong governance, better performance
Simpler architecture and faster deployment
Department-specific analytics with centralized governance
Limitations
More complex implementation and maintenance
Reduced scalability and flexibility
More complex data management
Best Suited For
Large enterprises and complex analytics environments
Smaller organizations and less complex reporting needs
Organizations with diverse business units and reporting requirements
Data Warehouse Design Process
Now that we’ve covered the key components, architecture types, and layers of the data warehouse design, let’s dive into how to design a data warehouse in seven steps, from business requirement analysis to data quality and integrity design.
Gather and Analyze Technical Requirements
Objective: Define the technical requirements that will shape the data warehouse design framework.
It all starts with defining your technical requirements for the data warehouse. They’ll stem from the business requirements already outlined in your data strategy.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“Many mistakes or inefficiencies in the data warehouse design are the direct result of misunderstanding what the business as a whole or specific end users need from the system. Skipping over this phase can also lead to underestimating the project scope, timeline, and budget.”
Your technical requirements should include specifications for data integration (ETL/ELT process, data quality validation), data modeling (schema design), and storage (partitioning and archiving). You should also outline requirements regarding data warehouse security (role-based access control), performance (indexing, query), and user accessibility.
With the technical requirements gathered and analyzed, you’re ready to start mapping out data sources for your future data warehouse.
Identify Data Sources
Objective: Map data sources and types that the data warehouse should consolidate.
Where will all that data come from? That’s the key question you should answer at this stage. It’ll inform your data model design, data transformation technique choice, integration strategy, and storage and computing resource requirements. You should also make sure you integrate all required sources to ensure data consistency, timely refreshing, and proper syncing.
To identify all the data sources:
- Map all data sources: applications, databases, file systems. etc.
- Assess each source’s relevance to the outlined business objectives.
- Analyze data volumes, variety, and velocity.
- Map data formats, structures, and dependencies as they appear in the source systems.
- Determine how often data should be extracted and updated.
With the data sources identified and analyzed, you can move on to designing the data models for your data warehouse.
Prepare Data Modeling Structures
Objective: Design the data model structure that reflects how data will be stored and related.
Now, it’s time to map how your data will be organized in a data warehouse. At this stage, it’s crucial to select the right schema and cover all attributes, dependencies, and relationships to ensure data reliability and consistency. Your architectural choices here will also impact the performance and scalability of the future solution.
To map out how the data will be organized in the data warehouse, take these three steps:
- Create a conceptual data model. This high-level overview defines the main entities and their attributes and visualizes dependencies between them (e.g., customers, products, transactions).
- Build on it with a logical model. Expand the conceptual model by defining the fields, relationships, and data types (but don’t focus on physical implementation just yet). Use the star or snowflake schemas to do it.
- Define data granularity. You can set a time-based frequency (e.g., daily or hourly updates) or an event-based one (e.g., per transaction). A higher frequency enables real-time analytics but increases storage requirements and can slow down queries.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“The star schema is the optimal choice if the data processing speed is crucial. However, the snowflake schema helps minimize data redundancy, which in turn optimizes storage and resource consumption.”
Based on the conceptual and logical data models, you can then assess the computing and storage resources and performance requirements at the following stage.
Outline the Physical Data Warehouse Design
Objective: Flesh out the implementation details, including storage and performance requirements.
Now, it’s time to ponder how you’ll implement your data warehouse in terms of its environment, partitions and indexes, storage technology, archiving, backups, and so on. The decisions you make during this stage will play a direct role in the data warehouse’s performance, scalability, and cost efficiency.
Here’s how to outline the physical data warehouse design in six steps:
- Select the environment (on-premises vs cloud-based vs hybrid).
- Design indexes and partitions with high performance in mind.
- Devise optimization strategies to maximize performance.
- Select the database management system (DBMS) that suits your requirements, data volumes, complexity, and data processing needs.
- Choose the optimal storage technology (e.g., columnar vs. row-based databases).
- Devise your approach to data compression, archiving, and backup that balances optimizing storage costs with ensuring prompt data availability.
With the infrastructure for your data warehouse outlined, you can move on to designing the ETL/ELT pipeline.
Design the ETL (Extract, Transform, Load) Pipeline
Objective: Outline how data will be extracted from source systems, transformed, and loaded into the data warehouse.
Now, it’s time to design the extraction, transformation, and loading processes, as well as refresh frequency, for your data warehouse. At this stage, make sure you select the right techniques throughout the pipeline to preserve data quality, consistency, and timeliness.
When designing the ETL/ELT pipeline, outline its three key phases:
- Extract: Outline the processes for pulling data from source systems.
- Transform: Map processes to ensure data quality, integrity, and consistency. They typically include data validation, cleansing, deduplication, conversion, formatting, and transformation (e.g., handling missing values, converting values).
- Load: Determine how data will be added to the warehouse and ensure it integrates well with the designed data model.
Then, consider the refresh frequency. There are three approaches you can choose from:
- Batch processing collects data in real time but transforms or adds it to the warehouse only after a specific batch size or time interval is reached. Key challenges of this approach include complex maintenance and cumbersome missing records handling.
- Real-time streaming continuously pulls and loads data from sources to enable real-time analytics. It comes with two key challenges: handling large data volumes and maintaining low latency.
- Hybrid approach combines batch processing and real-time streaming based on business needs and data types, allowing you to enjoy the best of both worlds.
Outline Data Governance and Security Measures
Objective: Define the framework for managing data privacy and security.
Your business probably has to comply with specific regulatory requirements (e.g., GDPR, CCPA), and non-compliance can entail both hefty fines and reputational losses. But even if it didn’t, overlooking data security can lead to data breaches – and one breach costs companies $4.88 million on average.
So, when designing a data warehouse, address:
- Who will manage and access data and what responsibilities each role will entail
- How you will secure data with encryption, authentication, access controls, etc.
- What processes, standards, and governance practices you’ll put in place to comply with regulations
- How you will manage data stewardship and metadata.
Make sure your data governance and security policies align with your enterprise-wide data management framework.
With the security and compliance practices outlined for your data warehouse, you can move on to the final stage of the design process: ensuring data quality and integrity.
Outline Data Quality and Integrity Controls
Objective: Ensure data accuracy, consistency, and quality.
Your BI tools’ output will be only as accurate and representative as the data you feed into them. To ensure that your datasets are reliable and trustworthy, you must implement effective data quality management practices.
To design proper data quality and integrity controls:
- Assess constraints and dependencies between data sources and types to ensure consistency.
- Establish validation processes to catch errors like out-of-range values and invalid data formats.
- Determine how you’ll handle common issues like duplicate records, null values, and data inconsistencies.
With this stage finalized, you can start preparing for the data warehouse implementation.
Dmytro Tymofiiev
Delivery Manager at SPD Technology
“Making data reliable means considering all the potential issues that can arise – and how your tools will handle them. To ensure data quality, analyze it through the lens of completeness, uniqueness, validity, timeliness, accuracy, consistency, and fitness for purpose.”
Before moving from design into implementation, organizations should verify that the core architectural, operational, and governance decisions have been addressed. The checklist below summarizes the key activities required to design a scalable and maintainable data warehouse.
-
Define business objectives and reporting requirements
-
Identify and prioritize data sources
-
Select the appropriate architecture model
-
Design conceptual, logical, and physical data models
-
Define ETL or ELT processing requirements
-
Plan storage, compute, and scalability needs
-
Establish governance, security, and compliance controls
-
Define metadata and lineage requirements
-
Implement data quality validation processes
-
Create a roadmap for implementation and future growth
Data Warehouse Design Best Practices
Getting the data warehouse design wrong can cost you dearly. If you fail to align it with your business strategy, you may need to rework the solution soon after deployment. Mistakes at this phase of data warehouse implementation can also undermine the solution’s performance, scalability, user-friendliness, and data ROI.
Here’s how we at SPD Technology design a data warehouse to facilitate implementation and turn the data warehouse into a long-term asset.
Full-Fledged Stakeholder Involvement
A robust, well-aligned data warehouse architecture is impossible to design without a full grasp of the underlying business goals and needs. Stakeholder involvement is also crucial to securing buy-in, boosting user engagement, and ensuring full alignment with business needs.
Stakeholders include both senior executives and future end users. As you involve them in the design process, keep your eye out for conflicting business requirements and select the right trade-offs. You should also make sure you don’t neglect stakeholders in specific roles or business functions.
SPD Technology’s approach: We conduct workshops and interviews to gain a full understanding of the solution’s purposes, the organization’s reporting needs, and success metrics. We also collaborate with future business users to define KPIs and data interpretation rules that align with their needs.
Effective Data Modeling
Proper data modeling powers data quality, accuracy, and alignment with business needs. Choosing the wrong schema or SCD technique can also lead to poor performance and flexibility.
When designing the data model, you need to focus on your data volumes and complexity to select the right option between snowflake and star schemas. When considering the Slowly Changing Dimensions (SCD) techniques, assess how important historical data is and factor in frequency and performance requirements.
SPD Technology’s approach: We strike a fine balance between normalized and denormalized structures to deliver the right combination of performance and flexibility. We also assess the client’s business requirements to identify the right SCD technique for handling changes in data. As for the schema, we typically opt for the star schema for its simplicity and performance; the snowflake one is usually more suitable for complex, normalized data.
Scalability and Performance Optimization
The way you design a data warehouse will directly impact the solution’s scalability and performance, as well as data availability and timeliness. There are four key optimization techniques you should pay attention to during data warehouse design: partitioning, indexing, materialized views, and data archiving.
SPD Technology’s approach: We implement large table partitioning to maintain top performance and efficiency as data volumes increase and balance indexing to facilitate data retrieval while maintaining high data loading performance. We also use materialized views to handle complex queries efficiently and suitable archiving strategies for rarely accessed data.
Streamlined ETL Processes
The design of your solution’s ETL pipeline will impact data quality, consistency, and integrity. So, when you map the ETL processes, focus on data quality management, implement incremental loading, and automate as many processes and workflows as possible.
When you’re outlining the ETL pipeline, make sure you rely on unified data quality standards to transform data. These standards should be established on the organization-wide level to facilitate data integration.
SPD Technology’s approach: We implement robust cleansing, validation, and error-handling procedures to ensure superior data quality. We also pay extra attention to reducing load times with incremental loading and automating ETL processes as much as possible to maximize process reliability, repeatability, and efficiency.
Governance, Security, and Compliance
Overlooking these three aspects of data warehouse design exposes your organization to potential data breaches, regulatory fines, and reputational losses. So, ensure your data warehouse is fully secure and compliant with applicable regulations.
To protect your data, implement robust data lineage and metadata management, as well as comprehensive access control. Conduct a thorough audit of applicable regulations before designing the data warehouse and translate their requirements into specific technical measures and processes, as well.
SPD Technology’s approach: We ensure your data remains traceable and transparent with thorough data source and transformation logging and monitoring. We also protect sensitive data with robust security mechanisms (e.g., RBAC).
Seamless Data Integration
When designing data integration processes, verify that all data can flow smoothly from sources of various types (e.g., databases, APIs, cloud platforms, flat files) into a single system. Otherwise, your teams may end up relying on stale data while data silos persist across the geographical and departmental lines.
To enable seamless data integration and maximize data consistency, categorize different types of data (master data, metadata, transactional and operational data, analytical data) to gain the proper visibility into your data estate. You should also identify data silos and get rid of them early on.
SPD Technology’s approach: To maintain consistency across business entities (e.g., products), we rely on master data management (MDM) practices like data synchronization, semantic consistency, and data stewardship.
Ensuring Adaptability and Maintainability
The data warehouse architecture design will directly impact the system’s agility and maintainability. So, you should ensure your data warehouse architecture is modular and flexible enough to facilitate future changes.
If you turn to an external partner to design a data warehouse, make sure the partner provides comprehensive documentation as a result of your collaboration. It’s vital for onboarding your in-house team and maintaining the system.
SPD Technology’s approach: We deliver modular architecture designs that allow for easy changes and updates so that your system can evolve as the business needs change. We also create comprehensive documentation for data models, business logic, and ETL/ELT processes to facilitate maintenance and onboarding for new developers.
How to Design a Data Warehouse: Team, Budget, Timeline
With the technical aspects and best practices of data warehousing design covered, let’s move on to the practicalities. Here’s what you should expect from a data warehouse design project in terms of team composition, budget, and timeline.
Team
Your team will need the narrow technical skills to design a high-performing, cost-efficient data warehouse, from data engineering and integration to data quality management. You’ll also need a business analyst to translate your business requirements into technical ones and a project manager to oversee the team’s progress and communicate with stakeholders.
Our team typically includes:
- Business analyst responsible for collaborating with key stakeholders to gather business requirements and align the solution with your goals and needs
- Data architect who designs the data warehouse, from ETL processes to data integration strategies
- Project manager in charge of coordinating the team and ensuring the timeline and budget are followed
- Data engineer who builds and maintains ETL/ELT pipelines
The team size depends on the project’s complexity and timeline, which are in turn determined by your business needs and goals.
Budget
A data warehouse design project can cost between $50,000 and $500,000 – or even more. The budget depends on:
- Project scope. More complex systems require more time and labor to design.
- Selected data warehouse environment. Cloud-based and on-premises systems have different cost structures to account for.
- Data volumes and sources. Data variety and amounts determine storage and ETL/ELT costs.
- Tech stack. ETL tools, database software, and analytics systems come with licensing fees.
- Team size and expertise. Project complexity and timeline determine team composition and required expertise.
In our experience, small and midsized projects for a data warehousing design typically cost between $50,000 and $200,000. A large project’s budget, however, usually starts at $500,000.
Timeline
Project scale and complexity determine the duration of a data warehouse design project. Specific requirements like complex data sources of multiple types, real-time analytics requirements, and strict regulatory compliance requirements also extend the timeline.
The project’s timeline consists of four major stages:
- Defining business requirements
- Designing the architecture
- Building ETL processes
- Testing and implementing the architecture.
In our experience, small to mid-sized projects take an average of 2 to 4 months to complete. Large-scale projects require 6 to 12 months but can take longer.
Designing a Data Warehouse: In-House or Outsourcing?
Given the complexity of the project and the specific skill set required, should you design your future data warehouse in-house or turn to a service vendor specializing in data warehouse design? We suggest choosing a proven strategy and going for comprehensive data expertise coupled with real-life experience in data warehouse design.
Consider Professional Services
Data warehouse performance, scalability, flexibility, maintainability, and cost-efficiency all hinge on its architectural design. Designing a data warehouse right from the get-go, however, requires hands-on experience and expertise to avoid poor architectural choices and design flaws.
Turning to a data warehouse development and implementation partner comes with a number of benefits:
- Your data strategy roadmap is implemented as fast as possible thanks to the partner’s know-how and time-tested best practices, tools, and methodologies
- Your system is perfectly aligned with your business needs and objectives, as well as security and compliance requirements
- Your data warehouse solution supports complex data integration and ETL processes while remaining as simple and easy to maintain as possible.
Why Choose SPD Technology for Data Warehouse Design?
We ensure the best business outcomes for our clients by following six key principles:
- Scalability by design: We ensure your data warehouse can grow and evolve together with your business.
- Optimized performance: Our solutions are designed to process complex queries smoothly and promptly, improving user experience and minimizing operational costs.
- Cloud-ready solutions: We help businesses move to the cloud or adopt a hybrid approach to benefit from lower running costs, superior scalability, and high availability.
- Security first: We implement top-tier encryption, access control, and data governance measures to ensure robust security and regulatory compliance.
- Ongoing support: We stay by your side post-deployment to ensure your data warehouse continues to show top performance and evolve with your business.
- Laser focus on ROI: We create our solutions with long-term value in mind to maximize your ROI and keep costs in check.
Key Takeaways
- A well-designed data warehouse creates a centralized and trusted environment for analytics and business intelligence.
- Data modeling decisions directly affect query performance, storage efficiency, and future scalability.
- ETL and ELT pipelines must support both current reporting requirements and future expansion.
- Governance, compliance, and security requirements should be incorporated during design rather than after deployment.
- Architecture choices influence implementation complexity, maintenance effort, and overall cost of ownership.
- Designing for adaptability reduces future rework as business requirements evolve.
In short: data warehouse design is the process of creating a scalable, secure, and business-aligned foundation for analytics, reporting, and enterprise data management. Effective data warehouse design transforms raw operational data into a scalable analytics platform.
FAQ
What are the most critical data warehouse design decisions that affect long-term scalability?
The most important scalability decisions involve architecture selection, schema design, storage strategy, ETL/ELT architecture, partitioning, indexing, and technology selection. These decisions determine how efficiently the warehouse handles growing data volumes, new data sources, and increasing numbers of users.
Organizations that prioritize scalability early often avoid costly redesigns later. Designing for future growth is generally less expensive than rebuilding data models, pipelines, and infrastructure after performance problems emerge.
What are the most common data warehouse design mistakes that require costly rework?
Common mistakes include skipping requirements analysis, designing only for current needs, selecting the wrong schema, neglecting governance and security requirements, and underestimating future data growth. Many projects also struggle because data quality controls are addressed too late.
Another frequent issue is treating the warehouse as a technical project rather than a business initiative. When business users are not involved in defining requirements and KPIs, the resulting architecture often fails to support real decision-making needs.
How much does data warehouse design and architecture consulting cost?
Data warehouse design and architecture costs vary based on complexity, data sources, regulatory requirements, and project scope. Mid-sized projects typically range from $50,000 to $200,000, while large-scale enterprise initiatives often require significantly higher investment.
Architecture consulting usually covers requirements analysis, data modeling, architecture design, governance planning, ETL/ELT strategy, security design, and implementation planning. Organizations often reduce risk by validating the architecture before committing to full-scale development.
What is the difference between a star schema and a snowflake schema in data warehouse design?
A star schema connects fact tables directly to denormalized dimension tables, making queries simpler and generally faster. It is often preferred for reporting and analytics workloads where performance and ease of use are priorities.
A snowflake schema normalizes dimension tables into additional related tables, reducing redundancy and improving storage efficiency. However, it typically increases query complexity and may reduce performance compared to a star schema. The right choice depends on reporting requirements, data complexity, and scalability goals.
How long does data warehouse design and initial build take before the first data is available?
Small to mid-sized data warehouse projects typically take 2–6 months, while large-scale initiatives may require 6–12 months or longer, depending on complexity and scope.
Initial data availability often occurs earlier through phased implementation. Many organizations deliver the first analytics-ready datasets within a few months while continuing to expand integrations, data models, and reporting capabilities over time.