
Not every business gets the same return on investment from data initiatives. Some gain more. Data-mature organizations see an ROI twice as high as their less data-mature counterparts.
Achieving this data maturity – and maximizing ROI – is easier said than done. For one, 43% of organizations experience data quality issues and don’t have complete confidence in the accuracy of their data. Furthermore, 78% of analytics and IT leaders struggle to leverage data to make data-driven decisions and drive better business outcomes.
Implementing a modern data warehouse is the first step toward capitalizing on your data, so let’s discover the best practices for doing it right.
Understanding the Basics of a Data Warehouse
To get started, let’s discover what a data warehouse solution is, how it can benefit your business, and how it works in various industries.
What Is a Data Warehouse?
A data warehouse is a system that collects data gathered from multiple source systems, transforms it to ensure data consistency and quality, and stores it in a single source of truth. Data warehouses use online analytical processing (OLAP) to analyze aggregated data.
Data warehouses prepare and supply data to analytics and business intelligence (BI) tools. They enable businesses to run a detailed analysis on large datasets of dynamically changing data.
Unlike regular databases or data lakes designed for raw storage, data warehouses can handle Big Data: petabytes of diverse structured and unstructured information at high velocity. The impact of Big Data and machine learning spans quicker decision-making, deeper insights, and more advanced automation.
Why Do You Need a Data Warehouse?
Building a data warehouse is an investment that pays off with:
- Improved data quality: The ETL pipeline ensures that data from multiple sources is complete, consistent, accurate, and valid, preventing the “garbage in, garbage out” scenario.
- Powerful data insights: Reliable, consistent data from a variety of sources powers actionable insights updated in real or near-real time.
- Enhanced decision-making: Data warehouses provide enterprise data to business users, enabling better decisions faster.
- Unified data governance: Storing data in a single system facilitates enterprise data management and governance, thereby enhancing auditability.
- Competitive edge: Standardized Big Data and advanced analytics allow businesses to identify new business opportunities more quickly than their competitors with siloed data.
Data Warehouse Use Cases
As a centralized data system, a robust data warehouse becomes an indispensable solution for businesses from multiple industries. For example, in finance, organizations use data warehouses to consolidate transaction data, client records, and market data. Centralized storage facilitates reporting and compliance and lays the foundation for automating anti-money laundering (AML) and know-your-customer (KYC) checks.
In insurance, data warehouses can aggregate claims records to run advanced trend analysis, consolidating customer data and third-party data to streamline fraud detection and prevention.
Retailers, in turn, can unify transaction and customer data to run analytics, gaining insights into customer behavior and product performance. A single source of truth for customer data also helps teams efficiently manage customer interactions and resolve support tickets faster.
Manufacturers implement data warehouses to unify supply chain, logistics, and inventory data in real time. This allows all teams to have real-time visibility into the inventory, supply, and order fulfillment. In construction, data warehouses can unify project performance data to enable real-time benchmarking against budget and timeline metrics and streamlining engineering reviews.
Energy producers can leverage a data warehouse to consolidate data on asset performance (e.g., grids, rigs, wind turbines) across locations. This data allows for balancing supply and demand and automating energy trading.
Finally, in e-commerce, data warehouses can aggregate customer, transaction, and operational data that can power CX personalization solutions and ensure timely order fulfillment. Analyzing historical data on product performance helps identify trends and inform optimal growth strategies.
Development of the Data Warehouse Strategy
To prepare for data warehouse implementation, you need to devise a comprehensive strategy first. Here’s how to do it in five steps.
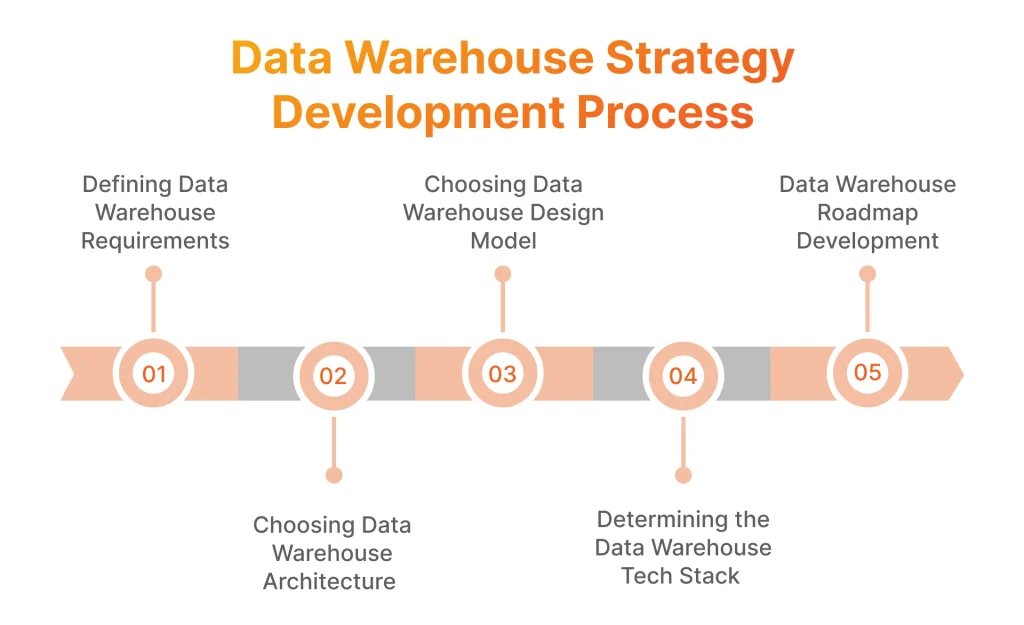
Defining Data Warehouse Requirements
The data warehouse business requirements will guide virtually every data architecture and planning decision, from your choice of environment and data integration to refresh frequency. They should align with your business objectives, metrics, and data needs, which should be defined before you start developing your data warehouse strategy.
As for data warehouse requirements, they should include data storage, integration, performance, governance, access, and reporting and analytics requirements.
Dmytro Tymofiev
Delivery Manager at SPD Technology
“Bring future data warehouse users on board and listen closely to their data and analytics needs. Besides ensuring your solution is designed to meet their needs, these discussions will also help you secure the buy-in among business users.”
Choosing Data Warehouse Architecture
The Inmon and Kimball methodologies are the two main approaches to building a data warehouse architecture, each with its own pros and cons.
Inmon Approach: The Top-Down Model
Proposed by Bill Inmon, this approach prioritizes creating a centralized data repository as the enterprise’s single source of truth. It also focuses on minimizing data redundancy and ensuring data integrity, quality, and consistency.
Under the Inmon approach, the engineering team first maps the corporate data model and identifies key entities and their relationships. After the unified data warehouse is built, the data, organized in a normalized model, is used to create data marts.
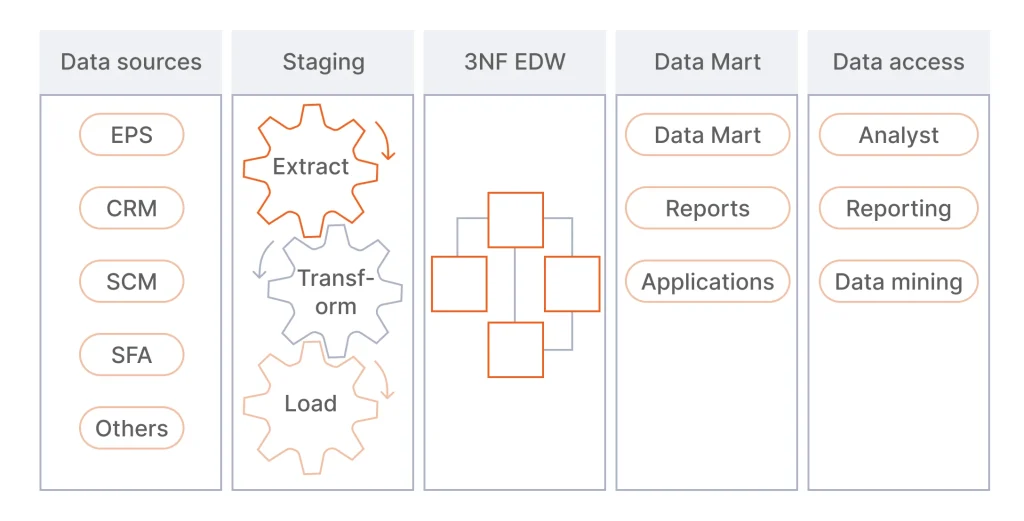
Pros:
- Minimized data redundancy and anomalies
- Higher flexibility and scalability
- Full overview of enterprise data in a single source of truth.
Cons:
- More resource-intensive in implementation
- Higher engineering overhead due to more complex ETL processes.
Kimball Approach: The Bottom-Up Model
Named after Ralph Kimball, this approach concentrates on building data marts for various business functions (sales, human resources, accounting, risk and compliance, etc.). It also uses a dimensional model (star/snowflake schema). Kimball advocated for building one data mart at a time, with future end users’ active participation in its design.
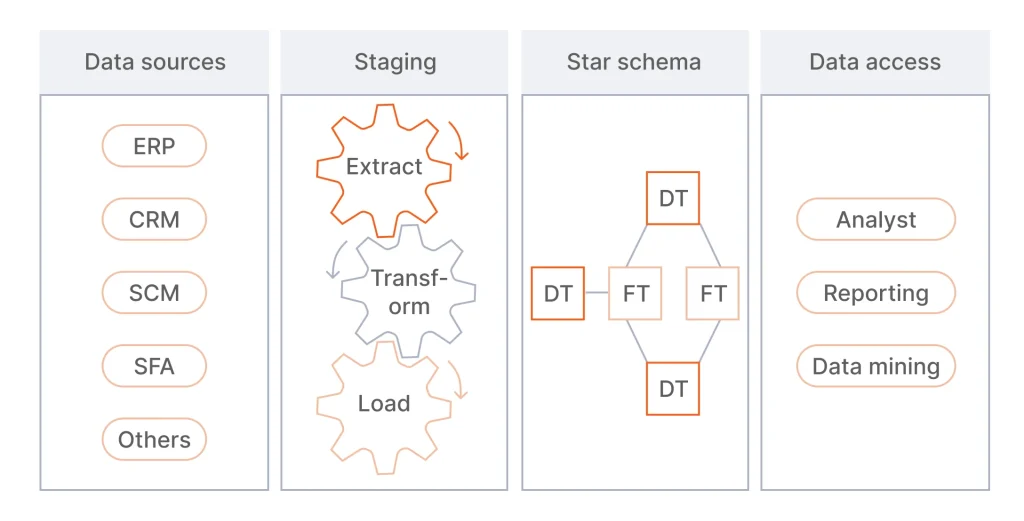
Pros:
- Quick implementation, making it suitable for organizations with limited resources
- High business user involvement in designing data marts
- Maximum data integrations’ relevance
- Easy-to-grasp data model.
Cons:
- Higher data redundancy and risk of errors
- Lower agility
- May not offer a 360-degree view of enterprise data.
Dmytro Tymofiev
Delivery Manager at SPD Technology
“The Inmon approach is more suitable for projects where governance and full overview of enterprise data are critical for complex reporting and strategic decision-making. The Kimball approach, on the other hand, is better suited for cases where organizations are limited in resources and need to have the analytics up and running as fast as possible.”
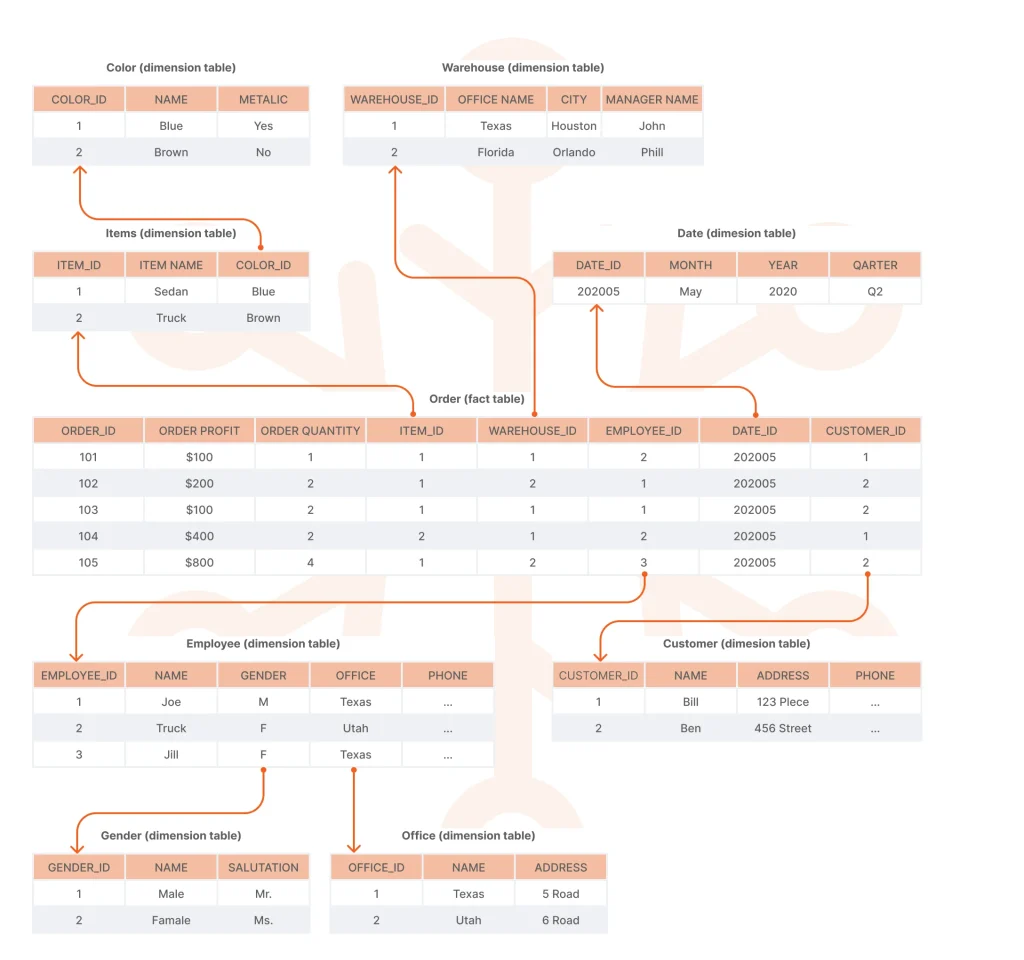
Data Warehouse Diagram
Based on the business requirements and selected architectural approach, create a diagram for your data warehouse. Visualizing the data flow is critical here. It should include the following five components:
- Data sources (business apps, SQL/NoSQL databases, IoT devices, etc.)
- Extract, transform, load (ETL) pipeline
- Warehouse database for storing the extracted data
- Metadata (e.g., data source, last modified date, author’s name)
- Access tools (OLAP, BI, etc.).
Data Warehouse Design: Choosing the Right Model
The way you organize the data in the data warehouse will directly affect its performance, scalability, and maintenance. Star and snowflake schemas are the two common blueprints for data modeling.
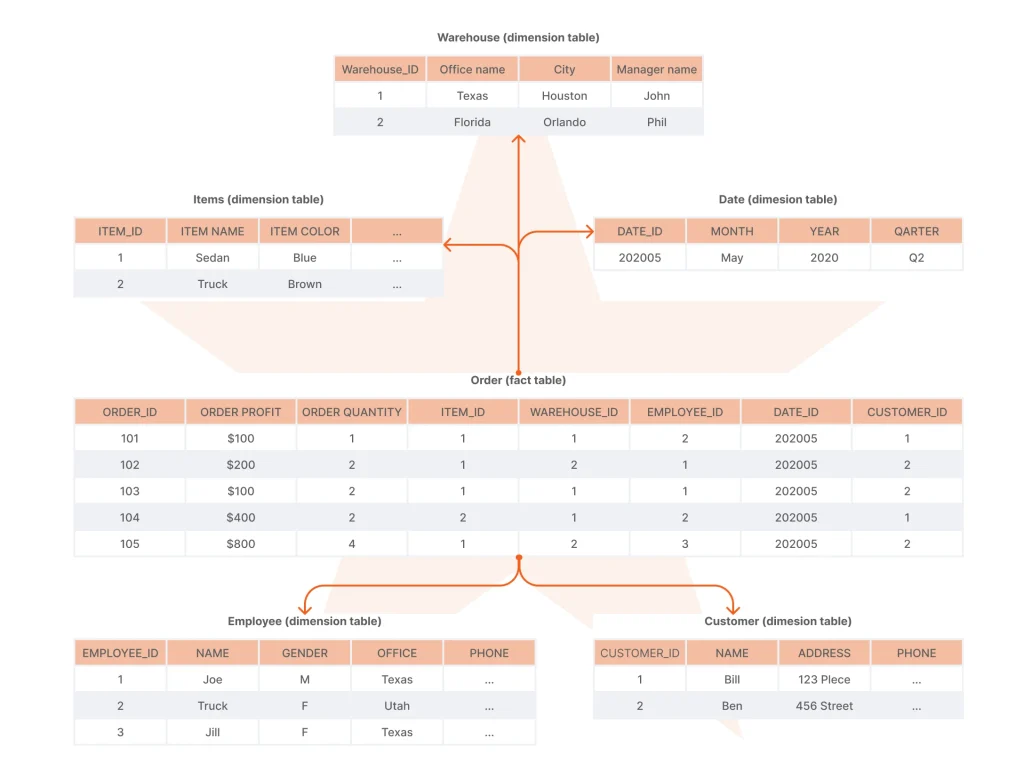
Star Schema
Under this schema, data resides in one fact table and is linked to denormalized dimension tables. This data structure is simple to implement and understand, and it enables higher data warehouse performance. However, those advantages come at the cost of higher data redundancy, increased storage requirements, and a greater risk of inconsistencies.
Snowflake Schema
The snowflake schema organizes data in a central fact table, connected to dimension tables, which are in turn linked to sub-dimension tables via foreign keys. This schema is better suited for complex queries, as it can accommodate complex and dynamic hierarchies and dimensions. However, it’s more complicated and may negatively impact query performance.
Want to dive into the nitty-gritty of designing data models for your data warehouse?
Check out our complete guide on data warehouse design, with best practices and insights from our experience.
Determining the Data Warehouse Technology Stack
The modern technology stack for a data warehouse includes:
- Data sources (databases, SaaS apps, event streams, etc.)
- Data integration tools (e.g., Stitch, Talend, Apache NiFi for batch processing; Apache Kafka and Snowpipe for real-time streaming)
- Data storage (e.g., Snowflake, BigQuery, Amazon Redshift, Azure Blob Storage)
- Data transformation tools that clean, standardize, convert, normalize, and filter data (e.g., DBT, Dataform)
- BI and analytics tools (e.g., Tableau, Power BI) and data science tools (e.g., Jupyter Notebooks, the DataRobot autoML tool, TensorFlow)
- Data governance (e.g., Egnyte, SAP Master Data Governance) and orchestration (e.g. Apache Airflow) tools
- Data versioning tools (e.g., Quilt, DVC, Pachyderm).
However, there’s no such thing as a one-size-fits-all tech stack for data warehouses. When selecting your data warehouse stack, consider your data sources and the integration capabilities you need. For example, data unification for legacy systems will require a somewhat different stack than modern SaaS systems.
On top of that, take into account your governance, security, and compliance requirements, the chosen environment (on-premises vs cloud platforms vs hybrid), data volumes, and data analytics needs.
Data Warehouse Roadmap Development
The data warehouse roadmap is a high-level overview of how you will get from point A (your current state) to point B (the fully functional data warehouse). It typically includes key phases (design, development, testing, and rollout) and the project scope and deliverables for each phase.
In addition to those sections, the roadmap should include the architecture vision and deployment strategy, as well as the approximate timeline and resources required for each phase.
How to Build a Data Warehouse: Step-by-Step Process
Building a data warehouse starts with careful project planning, followed by development, ETL pipeline implementation, data validation, testing, and deployment.
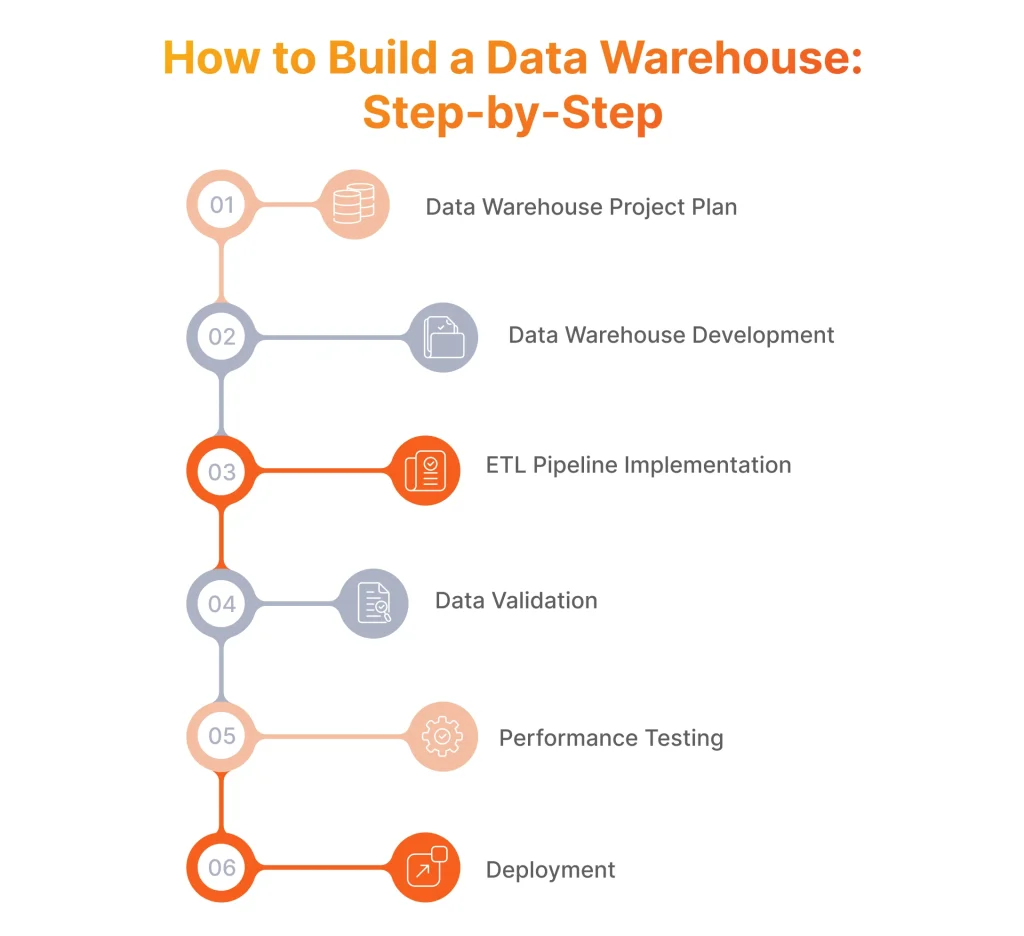
Data Warehouse Project Plan
Proper planning is key to securing the expertise you need to implement your data warehouse – and staying within the timeline and budget. Your project plan should include:
- Team size and composition
- Project scope
- Timeline with detailed objectives, key performance indicators (KPIs), and deliverables
- Budget, which should account for labor, licensing, storage, and ETL costs
- Estimates for the total cost of ownership (TCO) and return on investment (ROI).
It’s also a good idea to draw up a risk management plan as part of the preparation stage.
Data Warehouse Development
Based on the architecture and ETL pipeline design, your team can start building the physical warehouse, whether it’s going to be on-premises or in the cloud. This phase starts with setting up the infrastructure (plus virtual machines and storage buckets for cloud-based data warehouses). Then, your team needs to configure the storage and computing resources and implement the required security measures, such as access controls.
ETL Pipeline Implementation
This is where your team implements the outlined ETL processes in your data warehouse. Those processes span:
- Extracting source data from various source systems at the specified refresh frequency (batch processing/real-time streaming/hybrid approach)
- Transforming the extracted data to standardize it and ensure its consistency, reliability, and validity
- Loading the data to the centralized data storage following the selected data model.
Data transformations can take place before loading (ETL pipeline) or after (ELT pipeline).
Data Validation
During this stage, especially if validating data from a data lake, you need to ensure that the transformation logic applied in the ETL pipeline holds up. This means checking the loaded data for integrity, accuracy, validity, and consistency. Keep an eye out for error handling, formatting inconsistencies, unintentional changes, and corrupted values.
With data quality verified, ensure the transformed data is supplied on time and is fit for purpose. In other words, double-check that the data aligns with analytics and BI needs and business objectives.
Performance Testing
Will your data warehouse be able to handle future volumes smoothly and without performance gaps? By the end of performance testing, you should be able to give a positive answer to this question.
To make testing efficient, identify performance goals and design realistic test scenarios before developing and running the tests. Simulate varying levels of user load during load testing as well.
Based on the results, identify and resolve data warehouse performance bottlenecks, such as:
- Inefficient queries
- Performance gaps under specific stress conditions
- Logical data models in need of further optimization.
Deployment
With your data warehouse thoroughly developed and tested, it’s time to move it into production. It’s best to start with a rollout to a limited number of users and closely monitor the system for any data issues or areas of improvement. Known as a soft launch, it allows you to ensure the stability, efficiency, and performance of the final system in real-world conditions.
After implementing the final adjustments based on the soft launch results, you can fully deploy the data warehouse. But your work doesn’t stop here: you’ll need a team to oversee its performance, update and maintain it, and monitor data quality.
Data Warehouse Best Practices: SPD Technology’s Approach
To ensure your enterprise data warehouse (EDW) performs in line with your expectations, we rely on these six best practices in designing and building one.
Clear Understanding of Business Requirements
To ensure the highest ROI, we invest our time and energy in understanding the client’s business strategy, objectives, and requirements. This way, we can align the data warehouse architecture and implementation with existing needs and make resource allocation as efficient as possible.
To gain a complete understanding of your business needs, we engage key stakeholders across functions and lines of business early on. With their help, we pinpoint the key purposes of your future data warehouse solution, the reporting and analytics requirements, the metrics to track, and the data interpretation rules.
Proper Data Warehouse Structure
While working on an enterprise data warehouse (EDW), we identify data integration needs (including connections to a data lake) and expected volumes and user load to inform our design of the ETL processes and EDW data models. This helps maximize the ROI of your solution and avoid rework during development or soon after deployment.
To make the right architectural choices, whether you want to go with a central hub or a data mesh, we give extra consideration to how your business needs and objectives affect data organization (e.g., star vs snowflake schemas, normalized vs denormalized structures) and change handling (e.g., Slowly Changing Dimensions techniques). We also address metadata and data flow lineage management, partitioning and indexing, and the required business intelligence, analytics, and reporting capabilities.
Scalability and Performance
To build a data warehouse optimized for scalability and performance, we implement large-table partitioning to efficiently handle large volumes. We also prevent over-indexing while facilitating data retrieval and leveraging materialized views for complex queries. Finally, we ensure cost-efficient data archival optimized for query performance.
Data Warehouse Automation
To facilitate the upkeep of your future data warehouse, we implement ETL tools and automation throughout the whole lifecycle. They include tools for data exploration and modeling, ETL processes, and governance and security. We also streamline data collection, management, and maintenance with dedicated tools.
Data Quality Management
We develop a robust data management framework that ensures all data remains reliable and error-free in the EDW system. To do so, we consider the full range of transformations that may be required to promote data quality, such as:
- Cleaning: Rectifying errors and inconsistencies (data cleansing)
- Encoding: Converting categories into a numerical format to facilitate analysis
- Aggregation: Combining multiple entries into a single dataset or value
- Normalization: Standardizing data according to the pre-determined format
- Enrichment: Adding relevant information from external sources to the data loaded.
We also meticulously verify that data validation and error handling processes perform as intended.
ns and lines of business early on. With their help, we pinpoint the key purposes of your future data warehouse solution, reporting and analytics requirements, metrics to track, and data interpretation rules.
Proper Data Warehouse Structure
While working on an enterprise data warehouse (EDW), the identified data integration needs and expected data volumes and user load inform our design of the ETL processes and EDW data models. This helps maximize the ROI of your solution and avoid having to rework the solution during development or soon after deployment.
To make the right architectural choices, we give extra consideration to how your business needs and objectives affect data organization (e.g., star vs snowflake schemas, normalized vs denormalized structures) and change handling (e.g., Slowly Changing Dimensions techniques). We also address metadata and data lineage management, partitioning and indexing, and the required business intelligence, analytics, and reporting capabilities.
Scalability and Performance
To build a data warehouse that is fully optimized for scalability and performance, we implement large table partitioning for handling large data volumes efficiently. We also prevent over-indexing while facilitating data retrieval and leverage materialized views for complex queries. Finally, we ensure cost-efficient data archival optimized for query performance.
Data Warehouse Automation
To facilitate the upkeep of your future data warehouse, we implement automation tools throughout the whole lifecycle. They include tools for data exploration and modeling, ETL processes, and governance and security. We also streamline data management and maintenance with dedicated tools.
Data Quality Management
We develop a robust data management framework that ensures all data remains reliable and error-free in the EDW system. To do so, we consider the full range of transformations that may be required to promote data quality, such as:
- Cleaning: Rectifying errors and inconsistencies
- Encoding: Converting categories into numerical format to facilitate analysis
- Aggregation: Combining multiple entries into a single dataset or value
- Normalization: Standardizing data according to the pre-determined format
- Enrichment: Adding relevant information from other sources to loaded data.
We also meticulously verify that data validation and error handling processes perform as intended.
Regular Maintenance and Monitoring
You’ll need a team to oversee your data warehouse once it’s up and running. That’s why we provide our clients with ongoing support in maintaining, monitoring, updating, and extending data warehouses.
This ongoing support includes:
- Round-the-clock monitoring for ETL processes, data quality metrics, and system performance indicators
- Regular performance, data quality, and security audits and optimizations
- Updates and patch management
- Troubleshooting
- Scalability adjustments if they become necessary.
Data Warehouse Implementation: Team, Cost, Timeline
Here’s what you should expect from your data warehouse project in practice, from the team composition to the budget and timeline.
Team
The team size hinges on the project’s scope and scale, as well as the timeline. That said, our team typically comprises these six roles:
- Business analyst determines functional and business requirements and documents the solution’s scope
- Data architect designs the architecture and data governance strategy and provides suggestions for the tech stack
- Project manager draws up project scope and objectives, provides budget and timeline estimations, schedules project phases, updates stakeholders, coordinates the team, and monitors project performance
- Data engineer creates, implements, and maintains EDW data models and structures, data pipelines, and ETL processes
- Quality assurance engineer designs and oversees data warehouse testing and develops and maintains tests
- DevOps engineer sets up the infrastructure and CI/CD pipelines to automate development processes
Cost and Timeline
Data warehouses vary wildly in complexity and scale – and, therefore, cost. Project costs depend on the number, variety, and complexity of data sources and volumes. Data security, governance, and regulatory compliance requirements, the number of data flows and entities, and performance requirements also play a role.
When building a data warehouse, you should also factor in licensing fees, compute, and data storage costs.
Based on our experience, data warehouse projects fall into three categories, budget-wise:
- Small-scale: Up to five data sources, simple rule-based analytics, off-the-shelf BI tools, and structured data processing. Average cost: $70,000-$200,000
- Mid-scale: Up to 15 data sources, a combination of real-time streaming and batch processing, and AI/ML data analytics. Average cost: $200,000-$400,000
- Large-scale: Over 15 data sources with structured and unstructured data, sophisticated AI/ML prescriptive and predictive analytics, and advanced real-time/batch processing. Average cost: $400,000-$1,000,000
As for the project duration, it also depends heavily on the project scope and scale: data volumes, variety, sources, reporting and analytics requirements, the chosen environment, etc. Smaller-scale projects typically take 2 to 4 months, while larger ones can take between 6 and 12+ months.
Building a Data Warehouse: Professional Approach
You can decide to go it alone and leverage in-house resources – or turn to a professional data warehouse implementation partner for help. Let us make the case for the latter.
Why Consider Professional Services?
While relying on in-house resources is an option, there are five good reasons to hire an implementation partner:
- Established best practices and previous experience are instrumental in avoiding common mistakes and staying within the budget and timeline
- Your data warehouse will be perfectly aligned with your needs and objectives
- Streamlined development processes mean faster time-to-value for your business
- Domain experience and expertise maximize resource efficiency, manage costs, and mitigate risks
- Reliable partners remain by your side to continuously monitor, maintain, and optimize your data warehouse so that it evolves alongside your business.
Service vendors with experience in data warehouse implementation can also offer data strategy consulting to help you derive the maximum value from your data.
Why Choose SPD Technology for Data Warehouse Design?
At SPD Technology, we have the right combination of expertise, experience, and business acumen to drive the best outcomes for our clients. Our recipe for success includes:
- Scalability by design. We future-proof our solutions so that they can easily accommodate new data sources, increasing large volumes, and additional requirements.
- Optimal performance. We design data warehouses that successfully handle complex data queries, advanced analytics, and large data volumes, ensuring excellent user experience and cost-efficiency.
- Cloud expertise. We can help you move to the cloud smoothly and without unnecessary disruptions, all while mitigating risks and ensuring predictable delivery.
- Robust security measures. We embed all the necessary security measures (data encryption, access control, governance) to ensure data availability while keeping data safe and maintaining compliance.
- Ongoing support. We remain by your side to help you derive maximum value from your data warehouse with continuous monitoring, fine-tuning, and regular auditing.
- Maximized ROI. We build solutions that give our clients a competitive edge and drive long-term business value.
Conclusion
Building a data warehouse requires careful consideration and analysis of your business needs and objectives. Without it, it’s impossible to draw up precise functional and non-functional requirements for the data warehouse, design the architecture, and test it thoroughly.
Once your data warehouse is deployed, your focus should shift to ensuring it maintains its performance, scales as needed, and evolves together with your business.
Are you searching for a reliable data warehouse implementation partner? Let us design, develop, and deploy your data warehouse – and ensure its top-notch performance, flexibility, and scalability.
Contact us to discuss how we can build a data warehouse tailored to your data needs!
FAQ
What are the five main components of a data warehouse solution?
A data warehouse can be broken down into five main components:
- Data sources, from IoT device data to business applications, databases, and files
- Extract, transform, load (ETL) pipeline for pulling data from sources, preparing it for analytics, and adding it to storage
- Database that consolidates all collected, transformed, and loaded data
- Business intelligence, analytics, and reporting tools to enable access to data for business users
- Data management and control tools for implementing and monitoring governance and security.
What are the four stages of building a data warehouse?
Building a data warehouse involves:
- Defining business and functional requirements and outlining the project’s scope, budget, and timeline
- Designing the data warehouse architecture, data model, and ETL processes
- Setting up the infrastructure, developing the data warehouse, and implementing the ETL pipeline
- Testing the data warehouse for data quality and accuracy, as well as performance and scalability.
What is the concept of building a data warehouse?
In essence, building a data warehouse means designing, developing, and implementing a data warehouse solution. This EDW system would aggregate various data types from multiple sources, prepare data for further analysis, and enable users to query it or gain insights through analytics and BI tools.
What are the four layers of data warehouse architecture?
Data warehouse architecture spans four layers:
- The source layer includes all data sources (e.g., flat files, business applications, IoT devices, NoSQL/SQL databases)
- The staging layer aggregates and transforms the extracted raw data to prepare it for storage and analysis
- The data storage layer consolidates transformed data for storage
- The presentation layer allows users to access data, query it, and run analytics on it.