

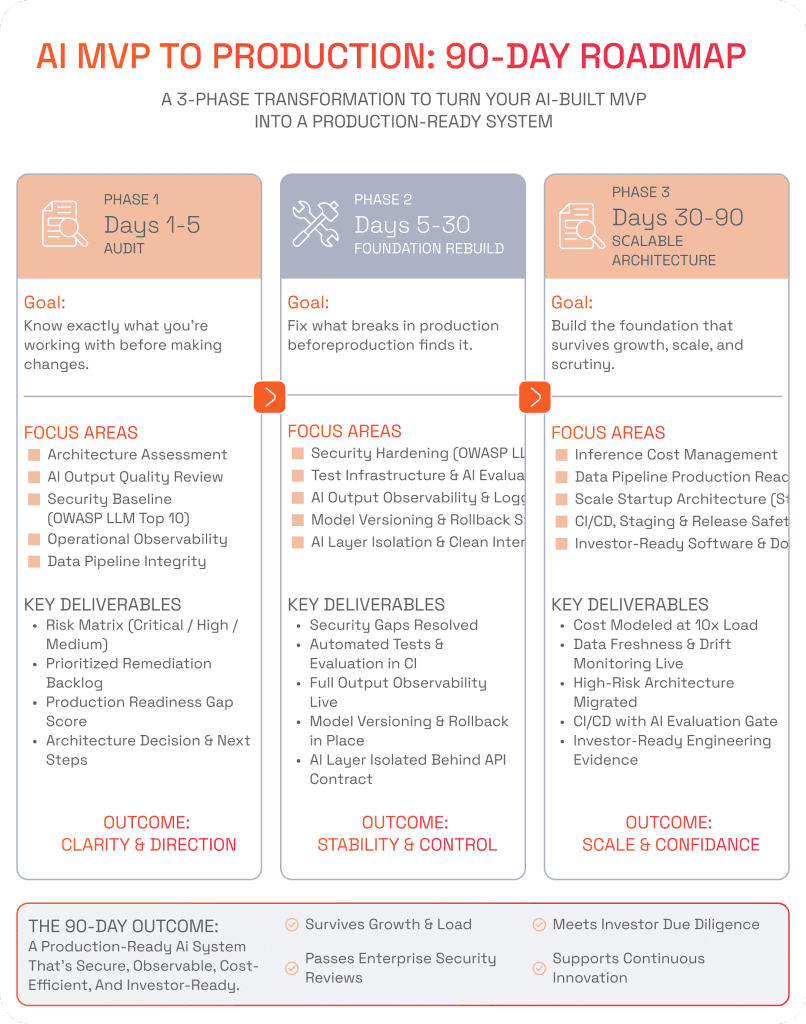
Moving an AI MVP to production takes about 90 days if done in the right order. Teams spend days 1–5 on a structured codebase audit, days 5–30 rebuilding the foundations (security, testing, observability, AI reliability), and days 30–90 scaling it into a production-ready architecture. Most AI-generated prototypes fail because they skip that initial deep audit.
When your vibe-coded minimum viable product (MVP) shipped, early users confirmed user needs and product-market fit, investors started paying attention, and an enterprise pilot landed on the table, it felt like the hard part was over. However, making a basic version of a system built for 50 users work for a growing userbase is a much harder problem than building the AI-built MVP itself.
Even though programmers generate code up to 45% faster with generative AI, there is also a growing concern that this speed creates technical debt that costs US companies $1.5 trillion in reduced productivity. The codebase is fragile, the architecture is tightly coupled with AI logic woven into every layer of the application, and there is no operational infrastructure around the AI layer.
This is why every expert team must understand that moving an AI MVP to production has to be thought-through and expertise-driven, and it can be done in as little as 3 months. This article is a 90-day engineering roadmap built specifically for teams that shipped with AI tools and now need to make the app real while the product concept keeps shipping and the team keeps building.
Why Turning a Vibe-Coded Prototype into a Production System Is Different From Standard Scaling
With a vibe-coded prototype, application foundations are often missing or fragile, so the work extends beyond scaling the design and involves repairing it while preserving what already works.
What AI-Built MVPs Have That Traditional MVPs Don’t and What They Lack
Standard prototypes usually establish basic engineering guardrails such as clear interfaces, test coverage, model versioning, logging, and security boundaries. But they require months to be built and validated.
A vibe-coded MVP, on the other hand, ships a set of minimum features fast enough to validate assumptions and gather feedback in weeks, instead of months of market research and usability testing, which can now happen in a few weeks of real user testing where beta testers and early adopters provide feedback. For example, we shared how we built an AI assistant MVP in 3 days and went from the demo to A/B testing in about 1.5 months to receive clear user feedback. However, these MVPs can lack everything around AI, and if used without caution, they can cause more harm than good in future work.
Gaps that surface during enterprise security reviews, VC technical due diligence, or the first serious production incident typically include:
- No isolation boundary around the AI as prompts live in UI components — hard to believe, but true, — API calls fire straight from business logic, and outputs flow into the data layer without contracts. VibeEval’s 2026 report shows OpenAI and Anthropic keys are frequently exposed in AI-generated frontend code, and a companion honeypot study found malicious requests typically start within six minutes of exposure.
- No tests for AI outputs as UI tests exist, but model behavior is not validated on every change.
- No model versioning strategy since production runs on whatever version the provider serves that day.
- No observability into the AI layer because prompt inputs and outputs are not logged, so past interactions cannot be retrieved or audited.
- No security review against AI-specific attack patterns since prompt injection, sensitive data exposure in outputs, and insecure model endpoints go unchecked.
The Three Layers of AI-Generated Code Debt That Standard Refactoring Misses
You start to see the difference between AI hype vs reality when AI-generated code debt shows up on three levels:
- Architecture debt is the structural mess that builds up over time. It shows up in unclear boundaries, tangled dependencies, weak data models, and logic that lives in the wrong place. And because AI-generated code carries 1.7x more critical and major defects than human-written code, that mess compounds faster than most teams realize.
- Quality debt is the gap between code that works once and code that can be trusted every day. As a result, 43% of AI‑generated code changes need debugging in production, often because tests, edge‑case handling, and quality assurance were missing at the MVP stage.
- Operational debt is what you pay when the system is hard to run, monitor, or recover. It shows up as weak logging, poor observability, no rollback path, unclear alerting, and manual fixes. Only 15% of GenAI deployments today have LLM observability, so most AI systems in production can’t answer basic questions about how the model behaves or learn from past interactions.
Why 90 Days Is the Right Window for MVP to Production Transformation
Gartner found that only 48% of AI projects ever reach production, and those that do take an average of 8 months. This is often too much when investments are at stake, and the 90-day structure is built to prevent such a drift. This period gives the MVP enough time to undergo a structured audit, rebuild the foundation, and complete the architecture work.
Anything shorter than 90 days forces foundation work and feature development to run in parallel. The team can’t do both well at the same time, so the refactoring stays shallow. Anything longer turns the transformation into an open‑ended project, where scope creeps, the product roadmap stalls, and engineering progress drifts away from business goals.
Days 1–5: The AI Prototype Audit — Know What You’re Working With Before You Touch Anything
Before starting a software product development process and fixes, the MVP must go through one of the most critical phases — an audit. A structured audit can identify areas of real risk, and catching them early saves resources later.
Why the Startup Codebase Audit Comes First and What Happens When Teams Skip It
Every engineering group that has tried to begin a transformation by repairing the most visible problems has only witnessed a deeper layer of issues surface almost immediately. An AI-built MVP is unusually good at hiding its weaknesses at the MVP stage while traffic stays light, and those weaknesses only reveal themselves when the system is asked to behave consistently for a larger audience.
To make sure these weaknesses are caught early, a startup codebase audit is required. It helps assess separate risk categories and generate a prioritized remediation plan with realistic effort estimates for every item. Each finding carries a classification that explains which necessary changes must be completed before the system can be exposed to a production environment.
What the Days 1–5 Startup Codebase Audit Covers
An AI-prototype audit helps assess architecture, AI output quality, security, operational readiness, and data pipeline integrity.
- The architecture assessment examines whether the AI component is genuinely isolated from the rest of the application. It checks whether prompt logic, model invocations, and output handling can be modified without disturbing business logic elsewhere, and whether an architecture diagram exists.
- The AI output quality review checks whether an evaluation suite exists and, if so, what’s in it. It also checks whether the team tests key outputs against ground‑truth examples, tracks hallucinations and edge‑case failures, and measures how model behavior changes across versions and prompts.
- The security scan allows auditors to review the codebase for prompt injection vectors, hardcoded secrets, missing input validation, exposed API endpoints, and gaps in row-level security at the database layer.
- Operational readiness checks whether prompt inputs and outputs are being logged in a form that allows past interactions to be retrieved and reviewed.
- The data pipeline integrity check considers how training data, retrieval sources, or fine-tuning datasets are versioned and refreshed.
What the Days 1–5 Audit of Minimum Viable Product Delivers as Outputs
Every audit finding is presented as a set of deliverables. The first is a risk matrix that shows how severe each issue is and how many engineering days it will take to fix. Building on that matrix, the next deliverable is a remediation backlog that prioritizes work by risk relative to effort.
Then comes a production-readiness gap score, which captures how far the current system is from the bar it must meet to be considered production‑ready. Finally, the audit ends with an architectural decision. Drawing on all findings, auditors recommend either targeted foundation work, where roughly 60% to 70% of the existing codebase is preserved and hardened in place, or a focused rebuild of a specific layer when the current implementation cannot be safely hardened without rewriting it.
Days 5–30: Foundation Rebuild — Fixing What Breaks Production Before Production Finds It
With the audit complete and the remediation backlog agreed, the development team can finally begin the work on the densest engineering load of the entire 90-day window, because every other phase depends on what gets built here.
Security Hardening for AI-Built Systems — What Standard DevOps Misses
Conventional security hardening already has a well-understood checklist that includes authentication, input validation, CORS configuration, content security policy, and rate limiting. Yet they are necessary but not sufficient with AI-built MVPs.
The most useful reference for thinking about security improvements is the OWASP LLM Top Ten. Typically, it highlights four security vulnerabilities in vibe-coded prototypes:
- Prompt injection
- Indirect prompt injection
- Sensitive data exposure through model outputs
- Unprotected model endpoints
The work during the first ten days of this phase directly addresses these issues. It is done through row-level security, secrets management, input validation, prompt injection detection, output sanitization, and rate limiting on model-facing endpoints.
Building the Test Infrastructure That Was Never Built on The MVP Stage
Most vibe-coded MVPs reach their first real users with almost no test coverage because the original development process and the AI tooling that generated the code did not push back against the lack of tests. Building this infrastructure now follows a clear order of priority:
- Smoke tests and performance testing cover every critical user flow and confirm that nothing fundamental breaks between deployments.
- Integration tests focused on the AI layer, checking the contracts between inputs and outputs ,rather than just the user interface.
- The AI evaluation suite creates a feedback loop on every model update and flags quality regressions before they ever reach customers.
AI Output Observability — Making the System Visible Before Scale Makes It Opaque
When it is required to check the ability to retrieve, review, and audit any specific interaction the model has had with a user from the system’s history (especially for Fintech, Healthtech, or LegalTech apps since observability is a compliance requirement), it is time for AI output observability. It separates a team that believes the AI is working from a team that can prove it is working when an investor, a regulator, or a customer asks.
The work for this phase covers four overlapping aspects:
- Logging captures every prompt input and model output along with timestamps, session identifiers, and user context.
- Structured tracing lets a single identifier pull up everything that happened during one user session weeks later.
- Latency instrumentation goes onto every model call so that performance degradation surfaces automatically.
- Inference cost is tracked per user session, which keeps the economics visible as the user base grows and usage patterns shift.
Model Versioning Strategy — Protecting Production from Silent Model Updates
Model versioning helps control the version of the model running in production. Version control helps prevent one of the most common failures in vibe-coding to production work when a silent model or prompt change breaks user‑facing behavior, but no one can trace what changed or who it affected.
It is done by pinning a specific model version in production, setting a clear policy that governs how new versions are evaluated against the existing one before adoption, and defining a tested rollback path for the system to return to the prior version when needed.
Isolating the AI Component — The Architecture Work That Makes Everything Else Possible
The architectural work is to extract the AI component into a dedicated service or module with a clearly defined input and output contract. All model calls are routed through this interface, and the rest of the application interacts with the AI only through that contract.
As a result, switching models becomes a simple configuration change. Caching can sit in front of the model without changing the app, evaluation frameworks run against the model contract, and cost optimizations, fallbacks, and multi‑model routing become much easier to implement.
Serhii Leleko
ML & AI Engineer at SPD Technology
“From day 5 to 30 is mostly about uncovering things the team did not know were there. Almost every project has a few of those moments.”
Days 30–90: Scalable Architecture — Building the Foundation That Survives Growth
With the foundation work complete, the system is no longer fragile, but it is not yet ready for growth. The next 60 days must focus on AI at scale to prepare the architecture, economics, and engineering evidence the team will need to expand product capabilities.
Inference Cost Management — Making AI Economics Sustainable at Scale
In a typical AI-delivered MVP, every user interaction triggers a direct uncached call to the model provider. It is cheap at low volume and expensive at scale. So, the work between days 30 and 60 addresses this on three fronts:
- Prompt caching is introduced to prevent identical queries from being charged twice.
- Model routing is evaluated, with cheaper models handling low-complexity tasks and the primary model reserved for interactions where its quality matters.
- Cost monitoring dashboards are added with per user and per feature breakdowns, so the team can see where the spend is concentrated and how unit economics shift as the product grows.
Data Pipeline Production Readiness for AI Systems
AI systems that rely on retrieval‑augmented generation (RAG), fine‑tuning, or structured data may have their data source broken. When that data system fails, the app can still look healthy while the model’s output degrades or breaks. Standard DevOps practices can often overlook this issue.
So, to make data pipelines in an AI system ready for production, it is essential to cover four areas, namely versioning of all training and retrieval datasets, data freshness monitoring with alerts when staleness exceeds a defined threshold, distribution shift detection, and, for RAG systems, keeping the embedding index in sync with the source documents.
Scale Startup Architecture — The Strangler Fig Pattern for AI-Coupled Code
For vibe-coded MVPs where AI is woven through every layer, the Strangler Fig pattern incrementally replaces a tightly coupled system behind clean interfaces.
This software refactoring strategy calls for identifying the highest-risk coupling points, typically AI calls embedded directly in UI handlers, business logic that reads model outputs without a contract, and database queries triggered by raw prompt responses. Clean interfaces are introduced around each of these, and layers are migrated to the new structure one at a time while the rest of the system continues to serve users.
CI/CD, Staging Environments, and the Deployment Safety Net
A vibe-coded MVP usually deploys from a developer’s machine or from a single-branch CI pipeline with no staging environment in between. Every production deployment is a direct risk event, and the team has no way to see how a change behaves under realistic conditions before customers do.
The following work requires DevOps expertise built specifically for AI systems, which includes the following steps:
- A staging environment is created that mirrors production across different platforms and operating systems, including model versions, data pipeline connections, and environment variables.
- Continuous integration is set up to run both the standard test suite and the AI evaluation suite on every merge.
- Canary deployment capability is added for model updates, so that a new version can be exposed to a small slice of traffic before being promoted.
Investor-Ready Software — What the 90-Day Endpoint Looks Like
Investor-ready software is an engineering evidence package that a technical due diligence reviewer can examine in roughly twenty minutes and come away confident. It implies that test coverage exists on the core AI logic and its outputs, output observability is in place with a retrievable interaction history, the OWASP LLM Top Ten has been addressed, model versioning is pinned with a documented rollback path, inference cost has been modeled at ten times the current load, and the staging environment, CI/CD pipeline, and data pipeline monitoring are all operational.
All that means that the system is ready for enterprise pilots, institutional investor due diligence, and the production load that arrives once user acquisition begins to scale the startup architecture toward real volume.
Serhii Leleko
ML & AI Engineer at SPD Technology
“The 90-day timeline is not obligatory, of course, but it reflects the practical engineering window a development team typically needs to turn a prototype into a production-ready system, stabilizing it, adding the missing guardrails, and shipping it without losing momentum or competitive advantage.”
AI MVP to Production: 90-Day Transformation Roadmap at a Glance
Here’s the table that walks you through the main steps involved in the vibe-to-scale process of moving an AI prototype to production.
Phase | Days | Focus | Key Deliverables | Risk if Skipped |
|---|---|---|---|---|
Audit | Days 1–5 | Startup codebase audit — AI-specific risk assessment | Risk matrix, prioritized backlog, architecture decision, production gap score | Fixing wrong things first; critical blockers discovered mid-transformation |
Security Hardening | Days 5–15 | OWASP LLM Top 10 — secrets, auth, RLS, prompt injection | All critical security findings resolved; no hardcoded secrets; API endpoints secured | Enterprise pilot blocked; investor due diligence fails; production incident |
Test Infrastructure | Days 10–20 | AI evaluation suite, smoke tests, integration tests | Safety net for model updates; regression protection on core AI outputs | 43% of AI code changes require production debugging without this |
AI Observability | Days 15–25 | Output logging, tracing, cost tracking, quality alerts | Full interaction history retrievable; latency and cost alerts active | Compliance blocker in regulated industries; debug blindness at scale |
Model Versioning | Days 15–25 | Pin versions, evaluation environment, rollback path | No silent production changes from provider updates; reproducible behavior | Silent degradation; inability to audit past outputs |
AI Layer Isolation | Days 20–30 | Extract AI component behind defined API contract | AI logic separated from business logic; clean interface for all model interactions | Every scaling initiative risks system-wide breakage |
Inference Economics | Days 30–60 | Prompt caching, model routing, cost dashboards | Cost modeled at 10x load; unit economics sustainable; cost alerts active | Margin collapse at growth stage; unprofitable at scale |
Data Pipeline | Days 30–60 | Versioning, freshness monitoring, distribution shift detection | No silent data staleness; retrieval quality tracked separately from generation | Silent AI degradation over weeks; user trust erosion |
Architecture | Days 60–90 | Strangler Fig migration of highest-risk coupling points | High-risk architecture replaced behind clean interfaces; no big-bang rewrite | Scaling initiatives require full system restarts or rewrites |
CI/CD + Staging | Days 60-90 | Staging environment, release gates, AI evaluation in pipeline | Every deployment validated in production-equivalent environment before release | Production incidents from untested model/data distribution differences |
Phase
Audit
Security Hardening
Test Infrastructure
AI Observability
Model Versioning
AI Layer Isolation
Inference Economics
Data Pipeline
Architecture
CI/CD + Staging
Days
Days 1–5
Days 5–15
Days 10–20
Days 15–25
Days 15–25
Days 20–30
Days 30–60
Days 30–60
Days 60–90
Days 60-90
Focus
Startup codebase audit — AI-specific risk assessment
OWASP LLM Top 10 — secrets, auth, RLS, prompt injection
AI evaluation suite, smoke tests, integration tests
Output logging, tracing, cost tracking, quality alerts
Pin versions, evaluation environment, rollback path
Extract AI component behind defined API contract
Prompt caching, model routing, cost dashboards
Versioning, freshness monitoring, distribution shift detection
Strangler Fig migration of highest-risk coupling points
Staging environment, release gates, AI evaluation in pipeline
Key Deliverables
Risk matrix, prioritized backlog, architecture decision, production gap score
All critical security findings resolved; no hardcoded secrets; API endpoints secured
Safety net for model updates; regression protection on core AI outputs
Full interaction history retrievable; latency and cost alerts active
No silent production changes from provider updates; reproducible behavior
AI logic separated from business logic; clean interface for all model interactions
Cost modeled at 10x load; unit economics sustainable; cost alerts active
No silent data staleness; retrieval quality tracked separately from generation
High-risk architecture replaced behind clean interfaces; no big-bang rewrite
Every deployment validated in production-equivalent environment before release
Risk if Skipped
Fixing wrong things first; critical blockers discovered mid-transformation
Enterprise pilot blocked; investor due diligence fails; production incident
43% of AI code changes require production debugging without this
Compliance blocker in regulated industries; debug blindness at scale
Silent degradation; inability to audit past outputs
Every scaling initiative risks system-wide breakage
Margin collapse at growth stage; unprofitable at scale
Silent AI degradation over weeks; user trust erosion
Scaling initiatives require full system restarts or rewrites
Production incidents from untested model/data distribution differences
How SPD Technology Makes an MVP Production-Ready in 90 Days
We give 90 days from MVP to production because, in our experience, this is the window that covers all three phases without any of them being rushed or stretched.
Why Most Teams Can’t Make a Full-Scale Product out of an MVP Alone
The people who built the MVP are usually the ones still shipping features. Take them off the roadmap for three months, and you lose the momentum that made the rebuild worth doing. This is specialist work — closer to software project rescue than feature development — and most internal teams don’t have those skills sitting around. Here at SPD Technology, our AI/ML development services provide the external resources and post-launch support that carry that load, letting the in-house team keep shipping.
The Vibe-to-Scale Engagement — The Same Three Phases, Delivered in 90 Days
The engagement is shaped around the specific failure modes of code generated on different platforms and tech stacks like Lovable, Cursor, Replit, Bolt, and Claude Code, taking advantage of the fact that our engineers have built on those stacks themselves to create products from zero to one. They know where the output holds and where it fractures under real traffic.
That experience changes what the work touches when you learn how SPD Technology’s vibe-to-scale service works in practice: the validated business logic from the MVP phase, typically 60-70% of the codebase, stays in place. What gets rebuilt are the architecture, quality, and operational layers underneath it, since these were never properly in place to begin with.
What the Free AI Prototype Audit Delivers — Early Stages with Days 1–5
We treat an audit as the entry point because guesswork at this stage is what sends the next ninety days sideways. A 30-40 minute working session with a senior SPD Technology solution architect walks through the same five categories covered in the Days 1–5 phase above and delivers a document with risks in your specific codebase, an architecture health assessment, and a sequenced set of next steps. This sets a solid foundation for your future development and provides certainty about what to do and why.
Key Takeaways
- Vibe-coded MVPs validate product ideas in days, but ship without the isolation boundaries, evaluation suites, observability, and model versioning required for production environments.
- AI-generated code carries 1.7x more critical defects than human-written code, and 43% of AI-generated changes require debugging in production.
- Skipping the days 1–5 codebase audit means teams patch visible problems first and discover critical blockers mid-transformation.
- Days 5–30 foundation includes rebuilding, which carries the densest engineering load of the entire window.
- Days 30–90 focus on architecture and use the Strangler Fig pattern to migrate AI-coupled code one layer at a time, behind clean interfaces.
- The 90-day window works because shorter timelines force foundation work to compete with feature shipping, while longer ones drift into open-ended rewrites.
In short: AI tools shorten MVP development from months to days, but production readiness still requires deliberate engineering across security, testing, observability, and architecture, which can be done in 90 days.
FAQ
How long does it take to turn an AI-built MVP into a production system?
The structured transformation takes 90 days when executed in the right order: days 1–5 for a codebase audit, days 5–30 for foundation rebuild, and days 30–90 for scalable architecture.
What is the difference between an AI MVP and a production-ready system?
An AI MVP proves the approach works and that users value it, while a production-ready system proves the same approach works reliably at scale, costs predictably as usage grows, and can be audited and modified without breaking.
Do I need to fully rewrite my vibe-coded MVP to make it production-ready?
No. The 90-day transformation preserves 60–70% of the existing codebase by isolating the AI component behind a clean interface, adding the missing test and observability infrastructure, and hardening the security layer.
What is the first step to moving an AI-built MVP to production?
The first step is a structured codebase audit that maps five risk categories (architecture isolation, AI output quality controls, operational observability, security baseline, and data pipeline integrity) and produces a remediation backlog.
What does investor-ready software mean for an AI-built MVP?
Investor-ready software is, in practice, a 20-minute read for a technical due diligence reviewer, a curated set of engineering artifacts that answers their questions before they ask.