Highlights
- AI-powered incident management solution — Incident Pilot — automates detection, analysis, and resolution of production incidents
- Cuts response time from 60+ minutes to under 30 minutes to pull request-ready fix
- Eliminates the need for 24/7 on-call engineering support, contributing resource optimization
- Handles incidents autonomously across time zones, ensuring continuous incident management
- Achieves up to 70% successful AI resolution rate with continuous improvement
- Transforms support cost model from 20–30% of engineering budget to predictable subscription
Client
The client is a US-based technology company running a production software platform requiring around-the-clock monitoring and rapid incident response. With their engineering team based in Europe, the client faced significant challenges managing cross-timezone production support while maintaining development velocity.
Incident Pilot was deployed by SPD Technology as both a proof of concept and a live operational tool. The client consistently reports feeling reassured by the agent’s instant response. Rather than waking up to an unresolved alert and radio silence, they see that the incident has been acknowledged, an issue has been created, and a fix is already in progress before their business day begins.
 Country
Country  Industry
Industry  Team Size:
Team Size: Product
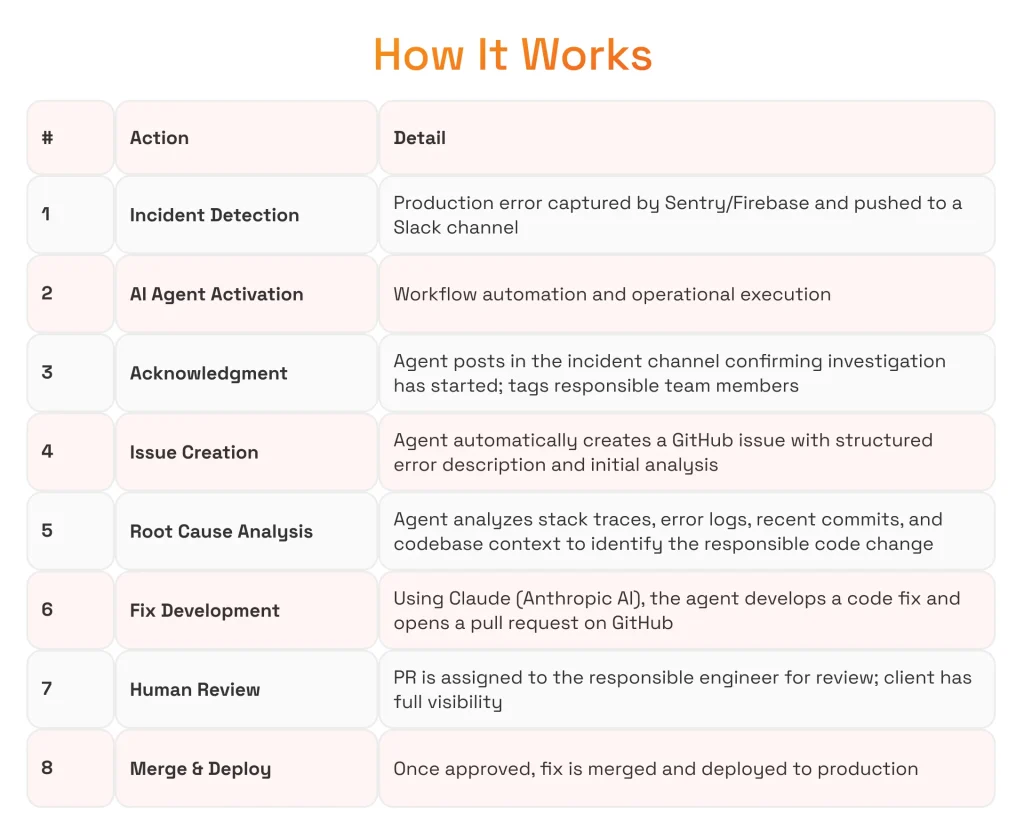
Incident Pilot is an AI-powered incident management agent that integrates directly with existing development infrastructure.
It autonomously executes the full incident response lifecycle:
- Incident detection
- Investigation and root cause analysis
- Issue creation
- Fix development (via AI)
- Pull request creation for human review
The core principle: mirror the exact workflow of a human engineer but execute it automatically in minutes instead of hours.
Goals & objectives
- Eliminate off-hours on-call burden. Remove the need for engineers to be woken up at night for production incidents, enabling morning reviews instead of middle-of-the-night firefighting.
- Reduce incident response time. Cut the average time from error detection to a proposed fix from 60+ minutes down to under 30 minutes, regardless of time of day or engineer availability.
- Lower support costs. Transform the cost structure from a variable 20–30% of the monthly engineering budget to a predictable, flat subscription model.
- Protect feature delivery velocity. Free engineering teams from the constant interruption of incident response so sprint cycles stay on track and features ship on schedule.
- Build institutional knowledge. Automatically generate structured root cause analyses for every incident, creating an organizational knowledge base that survives engineer turnover.
- Scale without linear cost increases. Handle unlimited parallel incidents at the same subscription cost, eliminating the need to scale on-call teams alongside growing system complexity.
Project challenge
Engineering teams maintaining production systems face a structural problem: incidents don’t follow business hours, but engineers do.
- On-call costs are disproportionate to incident frequency. In a traditional support model, 20–30% of the total monthly engineering budget is allocated to support contracts — most of which pays for human availability during quiet periods, not actual incident work.
- Time zone gaps cause dangerous delays. For US-based clients with European engineering teams, incidents happening at night trigger a slow, manual chain reaction: alert fires → engineer wakes up → logs in → reads context → investigates → begins writing a fix. By the time a fix is proposed, significant time has passed and business impact has accumulated.
- The manual response cycle is long by design. A typical incident flow: production error → alert in monitoring tool (e.g., Sentry) → Slack notification → engineer acknowledgment → GitHub issue creation → investigation → fix → pull request → deploy. Each handoff is manual, each step is sequential, and each requires a human to context-switch away from their primary work.
- Incidents interrupt feature delivery. Beyond the direct cost of incident response, the hidden cost is the work that doesn’t happen: sprint cycles disrupted, features delayed, engineers pulled out of flow.
Solution
SPD Technology developed and deployed Incident Pilot – an AI-powered agent that plugs into the client’s existing toolchain and autonomously manages the full incident lifecycle. The solution was designed around three core principles:
- Mirror the human workflow. Incident Pilot follows the exact same steps a human engineer would: detect the error, acknowledge it, create an issue, analyze root cause, develop a fix, and open a pull request. The only difference is speed and availability.
- Keep humans in the loop. The agent never merges code autonomously. Every fix goes through standard human code review before reaching production, preserving engineering accountability and quality standards.
- Reduce noise, not visibility. Smart deduplication and alert grouping ensure engineers only see unique, actionable incidents. Repeated errors are tracked silently and surfaced only when frequency spikes — eliminating alert fatigue without hiding information.
Our results
Operational Performance
- Incident acknowledgment: ~2 minutes
- Pull request ready: ~24 minutes after detection
- Deployment: next business day after human review
Before Incident Pilot, average time to a proposed fix exceeded 60 minutes — and that assumed the on-call engineer was reachable. Off-hours incidents regularly took longer.
Quality Metrics
- 65–70% incidents resolved correctly without rework
- 30–35% false positives (used to tune the agent’s prompts and repository documentation, improving accuracy for similar future incidents).
- AI performance: comparable to human engineers in most cases
Cost Structure Transformation
Institutional Knowledge as a Byproduct
Every incident handled by Incident Pilot generates a structured root cause analysis stored automatically. Over time, this builds an institutional knowledge base of failure patterns — without any manual documentation effort. Teams gain organizational memory that survives engineer turnover.
Highlights Client The client is a B2C company operating in the Healthcare industry. The mission of the company is...
Explore Case